
随着人工智能成为智能终端的核心组成部分,我们对计算性能的理解也需要与时俱进。对于许多工程师和产品团队而言,关注点仍停留在一个关键参数上:TOPS(每秒万亿次运算)。但在实际应用中,在边缘侧实现AI远不止于单纯的算力 —— 而是要在严格的系统约束下,实现快速、可靠且高效的智能表现。
为什么10 TOPS的AI芯片,连人脸识别都跑不流畅?
尽管 TOPS 能从理论上衡量芯片的 AI 性能,但它无法反映部署过程中真正重要的因素。一款 10 TOPS 的处理器在纸面上或许令人印象深刻,但如果模型超出了可用内存,或者硬件不支持必要的网络层或量化格式,那么在实际应用中,它无法发挥出全部的性能。
实际上,开发者经常会因为内存带宽、软件兼容性或芯片温度过高导致的降频问题使开发陷入瓶颈。对于摄像头、机器人等AI设备而言,真正重要的是在实际环境中运行模型的表现:是否具备稳定的帧率、低延迟和最低功耗。
低延迟和高吞吐量,谁更重要?
边缘AI与云端最大的不同在于云端追求“批量处理效率”,而边缘需要“单次响应速度”。降低延迟需要优化模型、减少预处理,并使用专为低延迟推理设计的硬件加速器(如神经网络处理器 NPU)。
边缘 AI 应用需要的是快速响应和高性能计算的结合。从辅助驾驶、实时翻译到智能制造业和医学影像,这些场景都依赖快速高效的处理能力,才能实现精准且及时的决策。无论是要让机器人反应灵敏,还是要进行高精度分析,各行业对可扩展的边缘 AI 计算的需求都在迅速增长。
为满足这些多样化需求,芯讯通(SIMCom)的AI算力模组产品提供了从 1 至 48 TOPS 的多样化选择,让开发者能够为边缘侧的各类实际场景定制解决方案。
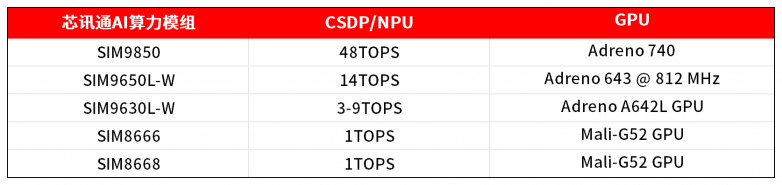
精度越高,AI效果越好?
当云端训练的模型带着FP32高精度来到边缘设备,等待它的往往是“水土不服”——飙升几倍的功耗,慢如蜗牛的响应。
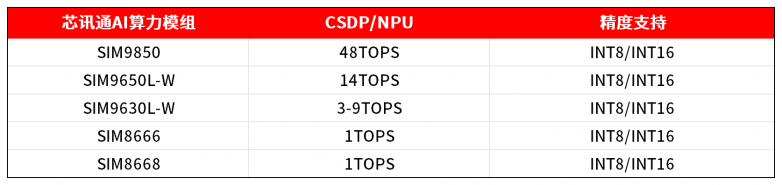
云端训练的 AI 模型通常采用高精度格式,虽能保证较高准确性,但会消耗更多电量和内存。对于边缘设备而言,量化(将模型转换为 INT16 或 INT8 等低精度格式)是一种广泛使用的简化技术。
然而,量化并非毫无风险。量化不当的模型可能会损失精度,尤其是在视觉复杂场景或光照条件多变的环境中。开发者应使用量化感知训练或训练后校准工具,确保精度下降不会对性能造成显著影响。选择支持混合精度计算的芯讯通AI算力模组,也能为平衡速度与精度提供灵活性。
硬件够强就行,软件不重要?
硬件只是成功的一半。如果没有强大的软件栈,即便是性能出色的AI芯片也可能成为研发障碍。开发者在模型转换、推理优化或系统集成过程中,时常会遇到各种问题。
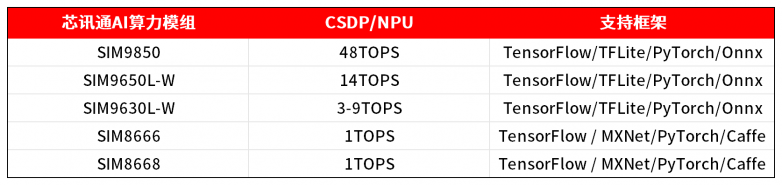
因此,选择具备成熟软件开发工具包(SDK)、工具链和框架支持的 AI 模组十分重要。无论使用 TensorFlow Lite、ONNX 还是 PyTorch Mobile,都必须支持流畅的模型转换、量化和运行时推理。芯讯通AI算力模组提供调试工具、性能分析工具和示例代码,这些都能加速开发进程并降低部署风险。
借助芯讯通(SIMCom)的AI算力模组,不仅能打造具备AI算力的产品,更能让其具备实用性、可靠性,适应现实世界的应用需求。
扫码了解专属边缘AI解决方案,让你的产品避开部署陷阱!
备注【AI算力模组】

