在当今数字化浪潮中,大模型技术正以前所未有的速度重塑各行各业。然而,大模型端侧部署长期面临着成本高昂与技术复杂的难题,让众多企业和研究机构望而却步。如今,端脑 Cephalon 携其革命性的 C1004A 算力一体机强势来袭,一举打破这一困局,为您开启大模型应用的全新篇章!

一、产品定位与核心价值
1.产品定位
端脑 Cephalon C1004A 是 Cephalon 团队自主研发的 AI 大模型推理一体机。它是全球首款能以 10 万元级预算运行 DeepSeek R1 / V3 这类超大语言模型(671B 参数级)的本地化设备,实现真正“满血版”私有部署。彻该一体机突破传统 GPU 集群部署高成本、高门槛的限制,以极致的工程设计、软硬件协同优化,为企业与研究机构提供高性价比、可扩展、安全可靠的大模型私有化部署平台。 ——这就是星球上最强的大语言和智能体服务器!
这意味着什么呢?以往运行这类大型模型,就像是驾驶一辆超级跑车,不仅购买成本高得离谱,后续的维护和燃料消耗也让人难以承受。而现在,C1004A 就如同将超级跑车的性能,装进了一辆经济实惠的家用车中,让您以超低的成本,享受顶级的算力服务。
2.颠覆传统

传统方案的降维打击
传统 GPU 方案:需近 10 张 A100 或 6 张 141G的 H20,成本超百万元,仅少数巨头可负担。
C1004A 方案:仅需 1 张 RTX 5090,搭配双路 Intel Xeon Gold 6438N CPU,以1/10 成本实现同等性能,甚至更优!
硬件架构的革命性突破
双路 Intel Xeon Gold 6438N(32 核 64 线程): 高带宽设计,实测内存交换速率 ≥75 GB/s,读取速率 ≥146.7 GB/s,远超 671B 模型推理所需的 ≥92.5 GB/s 带宽阈值,有效规避性能瓶颈。
异构计算黑科技:CPU+GPU 智能协同调度,攻克传统 CPU 算力不足、GPU 显存天价的双重困局。
结果体现在哪? 相比开源方案,端脑 Cephalon 推理引擎可提升性能 30%-50%,并在长文本推理、复杂指令执行等任务中保持稳定。
传统的计算方式,要么是 CPU 算力不足,就像一个人手不够的团队,工作效率低下;要么是 GPU 显存天价,成本让人难以承受。而 C1004A 的异构计算技术,就像是为这个团队找到了一群超级助手,CPU 和 GPU 能够智能分工协作,自研的推理引擎则像是给这个团队配备了一套高效的工作流程,大大提升了工作效率,攻克了传统 CPU 算力不足、GPU 显存天价的双重困局。
二、产品性能
1.端脑 Cephalon 算力一体机配置清单

2.暴力美学 · 细节:
a.全金属机箱结构,确保设备在 7×24 小时持续高负载运行下的稳定性与耐久性。
b.智能温控系统,确保关键组件(如 GPU 核心)温度稳定维持在 ≤65°C 的优化区间。
c.标配双万兆以太网接口,支持低延迟远程访问及多机集群扩展,满足规模化部署需求。

3.核心技术拆解
a.支持原版 DeepSeek R1/V3 模型运行
DeepSeek 是什么?—— DeepSeek 是中国领先的大语言模型开源项目,R1 / V3 版本参数规模高达 6710 亿,具备极强的语言理解、推理和代码生成能力,广泛应用于对话系统、知识检索、长文摘要、智能体等场景。
原版/“满血”意味着什么?—— 与市面上常见的“量化、剪枝、蒸馏”模型不同,C1004A 能运行完整结构的原始模型,模型精度与生成效果更自然、推理能力更强。
b.INT4 精度运行:节能 + 高效 = 性能极限释放
什么是 INT4?为什么重要?—— INT4 是一种将原始模型数值从浮点(如 FP16)压缩为4位整数的量化技术:
显著降低显存占用(降低部署门槛)
提高推理吞吐速度(节能降耗)
端脑 Cephalon 推理引擎实现 INT4 精度下的高还原度推理效果,真正兼顾速度与质量。
实际应用案例: 某大型民营医院部署 C1004A 处理患者问诊摘要任务,相比云端推理方案节省 60% 成本,同时保证输出质量,支持一天 8000+ 会话量。
4.性能优势
端脑 Cephalon 自研了推理引擎框架和极致的硬件选型,产品性能优势:
机器形态:机柜式,噪音低于 45dB。可以放置在室内空间
参数:满血全精度的R1,V3可选,同时可使用1种模型。理论上主参数 1T 以内的模型都能支持
配置:双路 Intel Xeon Gold 6438N +1 张 RTX 5090 高性能显卡
Cephalon 通过对推理引擎的独家优化提升了推理效率,是国内首个在 10 万价位内提供满血 INT4 精度模型28+tps速率的团队
Decode速率受上下文影响较小,可以稳定维持在 20tps 上下
Prefill 时间在 16k 上下文以内不超过 80s,和上下文长度成线性关系,16k 以上速度略有下降,极限长度 128k 上下文不超过 20 分钟
可配置各类调用大模型 API 的应用。

三、性能测试与数据解读
满血 INT4 精度
其他一体机对话速度:
1k 上下文:21.5 +TPS
16k 上下文:20 +TPS
128k 极限上下文:15 +TPS
C1004A 一体机对话速度
128 k 极限上下文:20 +TPS(行业领先)
其他一体机首字延迟:
16k 以内:≤80 秒
128k 极限:≤30 分钟
C1004A 一体机首字延迟
128k 极限:≤20 分钟(支持学术研究、代码生成等超长篇任务)
✅ 独家优势:
自研推理引擎使长文本处理速度提升50%(128k上下文20分钟 vs 竞品30分钟)
温度始终≤65°C → 7x24小时不间断运行(如同“永不发烧的AI工程师”)
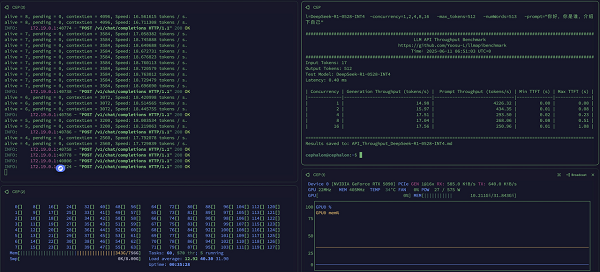

Cephalon C1004A 各类大模型并发数据
四、核心技术,铸就领先优势
1.端脑 Cephalon 自研推理引擎
a.核心技术解析:采用算子融合、高效内存管理、计算图优化等核心技术。
算子融合:提高了生产效率。
高效内存管理:能够合理地分配和使用内存空间,避免内存的浪费和冲突。
计算图优化:让数据在计算过程中能够更加高效地流动。
b.实际应用效果:实测在同等硬件条件下,针对 671B 模型,推理效率提升 >50%,显著优于通用方案。
在实际应用中,这些技术优势带来了显著的效果。比如在智能客服场景中,能够更快地理解用户的复杂问题,并迅速给出准确的回答。当用户咨询产品的多个方面信息时,C1004A 能够在极短的时间内对用户的问题进行分析、推理,并从知识库中提取相关信息,组织成清晰明了的回答反馈给用户,大大提升了客户满意度和客服工作效率。
2.动态异构资源调度
根据任务特性(如文本生成、逻辑计算)智能分配 CPU 与 GPU 计算资源,实现整体资源利用率最大化。
这就好比一个智能的项目经理,能够根据不同项目的特点,合理地安排团队成员的工作。当遇到文本生成任务时,它会分配更多的资源给擅长处理文字的 “成员”(CPU 或 GPU 的特定模块);当遇到逻辑计算任务时,又会把资源集中到更适合进行逻辑运算的 “成员” 手中。通过这种智能的资源调度方式,C1004A 能够在不同的任务场景下,都保持高效的运行状态,充分发挥硬件的性能优势,避免资源的浪费。
3.前瞻性兼容
架构设计预留充足算力冗余,支持未来演进至 1T 参数级别的大型模型。
这就像是建造一座房子,在设计时就考虑到了未来家庭人口的增加和需求的变化,预留了足够的空间进行扩建。随着技术的不断发展,大模型的参数规模也在不断增大。C1004A 的前瞻性兼容设计,让它能够轻松应对未来模型发展的需求,无需您在短时间内再次更换设备,为您节省了成本,保障了投资的长期价值。

五、多元应用,赋能企业与开发者
1.企业级落地
智能客服中心: 支持超长上下文(128k),精准理解复杂查询;≥416 TPS 的高吞吐量实现近实时交互,有效提升客服效率与体验。
这意味着在业务高峰期,大量客户同时咨询时,C1004A 也能快速响应,让每一位客户都能感受到高效、优质的服务,避免客户因为等待时间过长而流失。
长文档智能处理: 高效处理 128k+ 文本,自动化执行摘要、信息提取等任务(≥20 TPS),大幅提升知识管理效率。
在金融行业,对大量的财报进行分析时,C1004A 能够迅速提取出财务数据、业务亮点、风险提示等重要信息,为企业决策提供有力支持。
私有数据分析与洞察: 本地化安全运行,基于私域数据进行推理分析,实时生成结构化报告与可视化结果。
通过对客户购买行为、市场趋势等数据的挖掘,企业能够获得独特的洞察,为产品研发、市场营销等决策提供数据驱动的支持。而且,它能够实时生成结构化报告和可视化结果,让企业管理者能够直观地了解数据背后的信息,快速做出决策。
智能代码生成与辅助: 深度理解开发需求,提供高效的代码建议与补全(≥20 TPS),加速软件开发周期。
当开发人员需要实现一个特定功能的代码时,C1004A 能够参考大量的代码库和编程经验,给出准确、高效的代码建议,帮助开发人员节省时间,提高开发效率,加速软件开发项目的进程。
2.开发者生态
全开源兼容:全面支持主流开源大模型框架(如 LLaMA, Qween,ChatGLM, DeepSeek 等),提供便捷的一键部署流程;
一键部署流程让开发者无需花费大量时间和精力去配置复杂的环境,就像安装一个普通的软件一样简单,大大降低了开发门槛,让开发者能够更快地将精力集中在模型的优化和应用开发上。
集成 Agent 开发框架: 内置工具支持智能体(Agent)应用的快速构建,包括多工具调用、状态与记忆管理等功能;
例如,在开发一个智能购物助手时,开发者可以利用框架中的多工具调用功能,调用商品数据库、价格比较工具等;利用状态与记忆管理功能,记录用户的购物偏好和历史记录,从而为用户提供更加个性化、智能化的服务。
极简运维: 降低使用门槛,使小型团队也能高效利用前沿大模型能力。
对于小型团队来说,运维复杂的大模型系统往往是一个巨大的挑战,需要专业的技术人员和大量的时间精力。而 C1004A 的极简运维设计,让小型团队也能轻松上手。
端脑 Cephalon C1004A:高性能私有化大模型部署的专业之选
以精密工程与创新架构,将前沿大模型能力赋予每一家企业与开发者。
「免责声明」:以上页面展示信息由第三方发布,目的在于传播更多信息,与本网站立场无关。我们不保证该信息(包括但不限于文字、数据及图表)全部或者部分内容的准确性、真实性、完整性、有效性、及时性、原创性等。相关信息并未经过本网站证实,不对您构成任何投资建议,据此操作,风险自担,以上网页呈现的图片均为自发上传,如发生图片侵权行为与我们无关,如有请直接微信联系g1002718958。
