
通过Windows AI Foundry,您可以使用搭载各种Windows内置模型的Windows AI API集成人工智能。针对Windows Copilot+ PC上的超低延迟性和高性能对这些模型进行了优化。您可以使用LoRA(低秩自适应)、语义搜索和大型语言模型知识检索等Windows AI API,并结合自己的本地数据定制各种内置模型。Foundry Local提供了对一系列即用型开源模型进行快速访问的功能。

Windows AI Foundry示意图
根据微软Build开发者大会上发布的内容,Windows机器学习平台是一种搭载了ONNX 运行时引擎 (ORT) 的统一高性能本地推理框架,并对整个IHV生态系统的全面优化。Windows机器学习平台自动将应用程序绑定到客户端设备上最好的可用芯片。
下文列出的Windows机器学习平台主要特性为不断迭代的芯片提供了良好抽象:
· 处理IHV依赖项的分布,例如NPU的编译器、运行时和驱动程序。
· 将各种模型自动绑定到正确的芯片上,以便执行。
· 应用程序不再需要显式枚举并绑定到NPU/GPU/CPU提供程序。
应用程序仍可保留明确指定首选执行目标的能力(例如:仅在NPU上执行)。另外,应用程序也可以利用我们的智能设备选择策略,例如:高性能、高效率或最小功耗。
从2025年初开始,高通与微软密切合作,使用Windows机器学习平台和高通NPU执行提供程序(QNNEP)在高通NPU上开发和优化Windows AI Foundry 模型。
下图说明了基于Windows 机器学习AI应用程序的构建模块。该应用程序包括两个方面:
· 使用Windows机器学习平台基础架构API下载异步执行提供程序
· 使用Windows机器学习API进行AI推理。
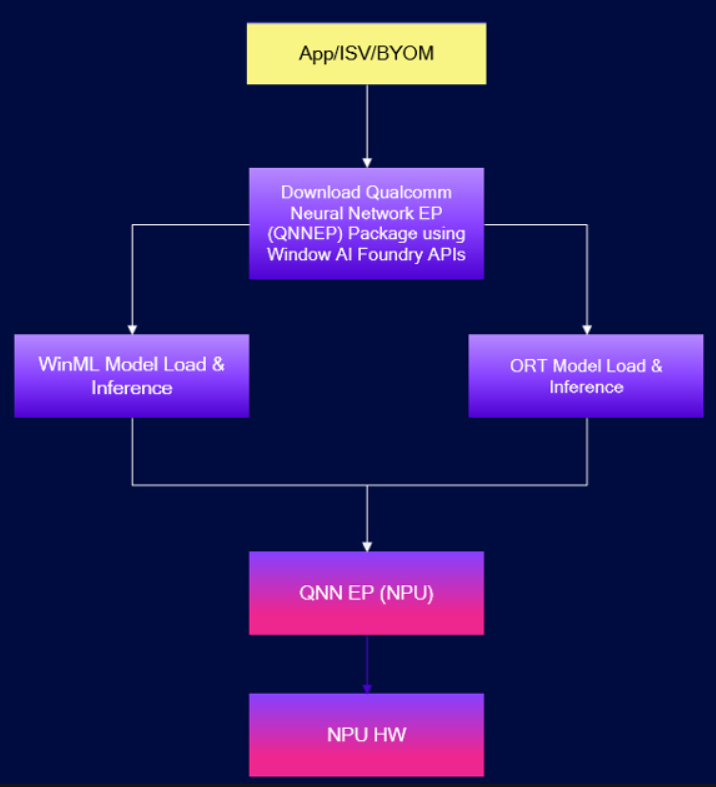
附图2:Windows AI Foundry应用程序
开发Windows AI Foundry应用程序的先决条件是通过微软商店下载并安装Windows AI Foundry MSIX。
通过Windows AI Foundry API下载所需要的执行提供程序包
以下API序列将所需要的IHV特定执行提供程序(高通NNEP)二进制文件下载到系统中。
- winrt::Microsoft::Windows::AI::MachineLearning::Infrastructure infrastructure;
- infrastructure.DownloadPackagesAsync().get();
- auto executionProviders = infrastructure.LoadExecutionProvidersAsync().get();
用于会话创建和推理的Windows机器学习API
- 选择推理设备:LearningModelDeviceKind deviceKind = LearningModelDeviceKind::Default;
- 选择会话选项:LearningModelSessionOptions sessionOptions;
- 创建会话:LearningModelSession session = LearningModelSession{…};
- 绑定输入与输出资源:LearningModelBinding binding = LearningModelBinding{session};
- 评估模型:LearningModelEvaluationResult results = session.EvaluateAsync(…).get();
用于会话创建和推理的ONNX Runtime API
- 设置会话选项:Ort::SessionOptions session_options;
- 分配输入与输出张量:session.GetInputCount() session.GetOutputCount()
- 编译模型:Ort::Status compileStatus = Ort::CompileModel(env, compile_options);
- 推理模型:session.Run()
使用Microsoft Olive对骁龙平台进行生成式人工智能和大型语言模型优化
Olive是一种高等级IHV不可知框架,可用于下载针对Hugging Face的模型、进行量化处理、运行推理、检查准确性和延迟率等。在高通NPU上,可以使用搭载高通NNEP的ORT或WinML执行由Olive生成的ONNX模型。Olive提供CLI和Python接口,并将JSON文件作为配置输入,从而在输入ONNX模型上执行所有必要的图形转换。例如:olive run -config resnet_ptq_qnn_qdq.json。
随着Windows AI Foundry在2025年第一季度的出现,高通技术公司的AI工程团队与微软公司密切合作,使用微软Olive工具链优化骁龙NPU上的几个关键生成式人工智能模型和大型语言学习模型。本节重点介绍这些优化的关键技术方面,以帮助开发者为骁龙平台优化其模型。
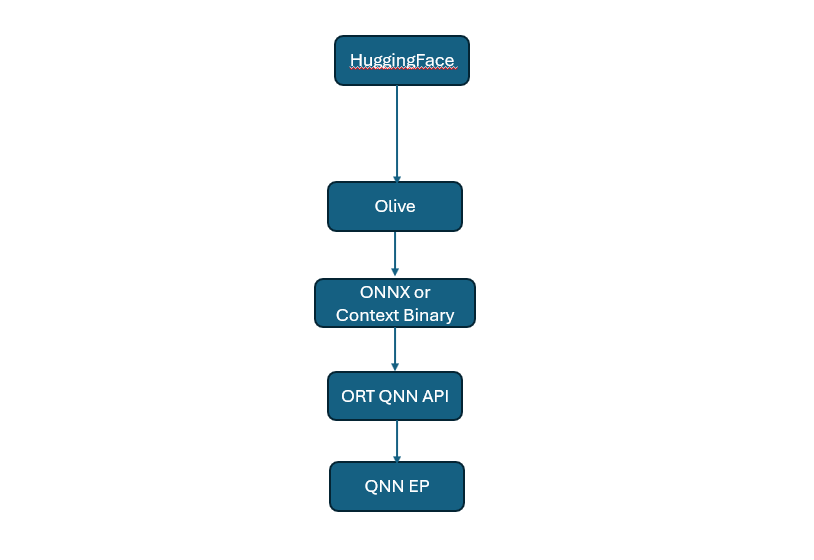
附图2:用于骁龙平台的Olive开发者工作流
用于高通NPU的Olive配置方案
| 模型名称 | Hugging Face链接 | 高通Olive配置方案 |
| CLIP ViT-B/32 - LAION-2B模型卡 | ||
| OpenAI模型卡:CLIP 32x32 | ||
| OpenAI模型卡:CLIP 32x32 | ||
| 视觉变换器(基础尺寸模型) | ||
| BERT多语言基础模型(封装) | ||
| INT8 BERT基础未封装微调MRPC | ||
| DeepSeek R1蒸馏 | https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B | |
| Phi 3.5 mini instruct | ||
| Llama-3.2-1B-Instruct |
Olive高级开发者工作流
1. Hugging Face到ONNX转换
2. 将动态形状输入转换为固定尺寸
3. OnnxStaticQuantizer:用OnnxStaticQuantizer量化模型。
4. EPContextBinaryGenerator:生成带有嵌入式执行提供程序环境的ONNX模型。
5. CaptureSplitInfo/SplitModel:将一个较大的模型分割成较小的部分
6. GraphSurgery:在Olive计算图手术中可用的图形转换。
结合以下量化技术和图形手术来优化骁龙平台的性能
1. MatmulAddFusion:将Matmul & Add选项融合到GeMM操作符,并针对qnn进行了优化。
2. ReplaceAttentionMask:将大的负注意掩码值剪辑为-1e4,以提高量化效率
3. RemoveRopeMultiCache:消除跨KV缓存的冗余RoPE计算
4. AttentionMaskToSequenceLengths:在运行时控制上下文长度
5. Simplfiedlayernormtol2norm:将基本层规范选项转换为更有效的L2规范
6. 权值旋转:减少权值和隐藏状态的异常值,以提高量化效率。
7. GPTQ:每通道4位对称量化,减少变换器层大小,同时保持精度。
8. ONNX Graph Capture:将模型导出到ONNX上,以进行进一步优化。
9. 4位模块量化到嵌入层和语言模型头。
参考内容
- 什么是Azure AI Foundry?- Azure AI Foundry | 微软学习
- 什么是Windows Copilot Runtime?
- microsoft/Olive: Olive: 简化有关CPU、GPU和NPU的机器学习模型微调、转换、量化、和优化。
- Windows机器学习简介 | 微软学习
- ONNX Runtime网站上的高通AI Engine Direct执行提供程序
在所发布内容中表达的观点仅为原作者的个人观点,并不代表高通技术公司或其子公司(以下简称为“高通技术公司”)的观点。所提供的内容仅供参考之用,而并不意味着高通技术公司或任何其他方的赞同或表述。本网站同样可以提供非高通技术公司网站和资源的链接或参考。高通技术公司对于可能通过本网站引用、访问、或链接的任何非高通技术公司网站或第三方资源并没有做出任何类型的任何声明、保证、或其他承诺。
骁龙与高通品牌产品均为高通技术公司和/或其子公司的产品。
关于作者
戈库尔·通佩 首席工程师
