在高通跃龙QCS6490设备上部署运行YOLOv10模型并使用NPU加速
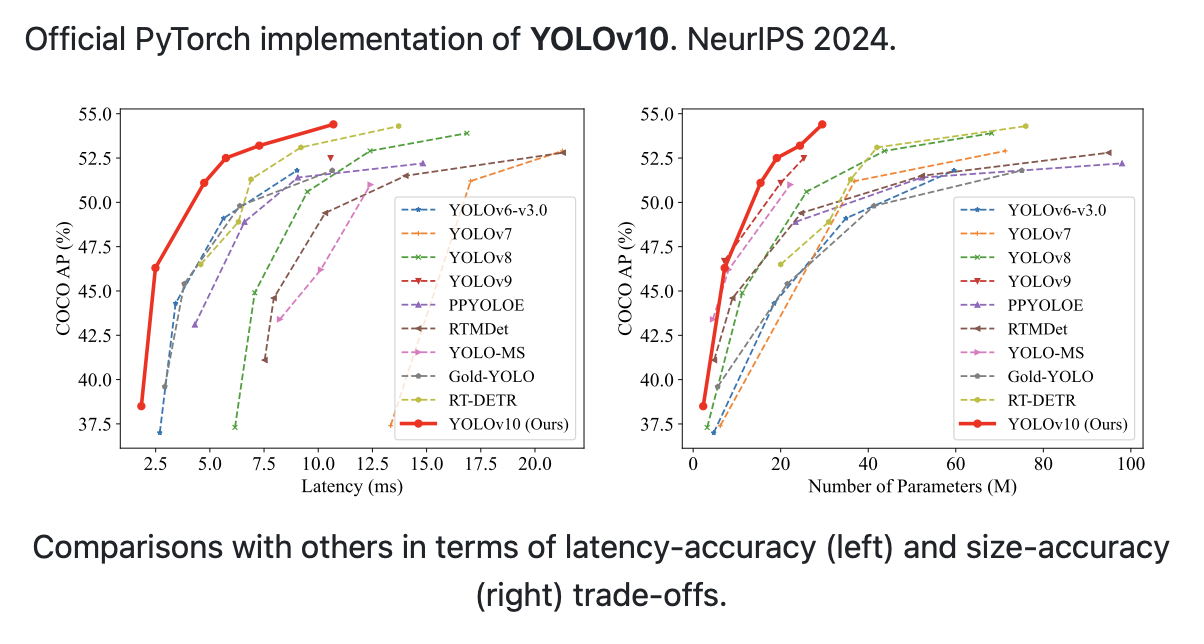
如图所示,YOLOv10 在准确性和效率方面都优于以前的YOLO版本和其他最先进的模型。
本文将介绍如何快将YOLOv10 部署在高通跃龙™ QCS6490设备上,并使用NPU加速。
本文所使用的软硬件:
硬件——高通AIBox6490,可以点击
AidLux了解更多设备参数信息
软件——内置AidLux企业版
部署方法:
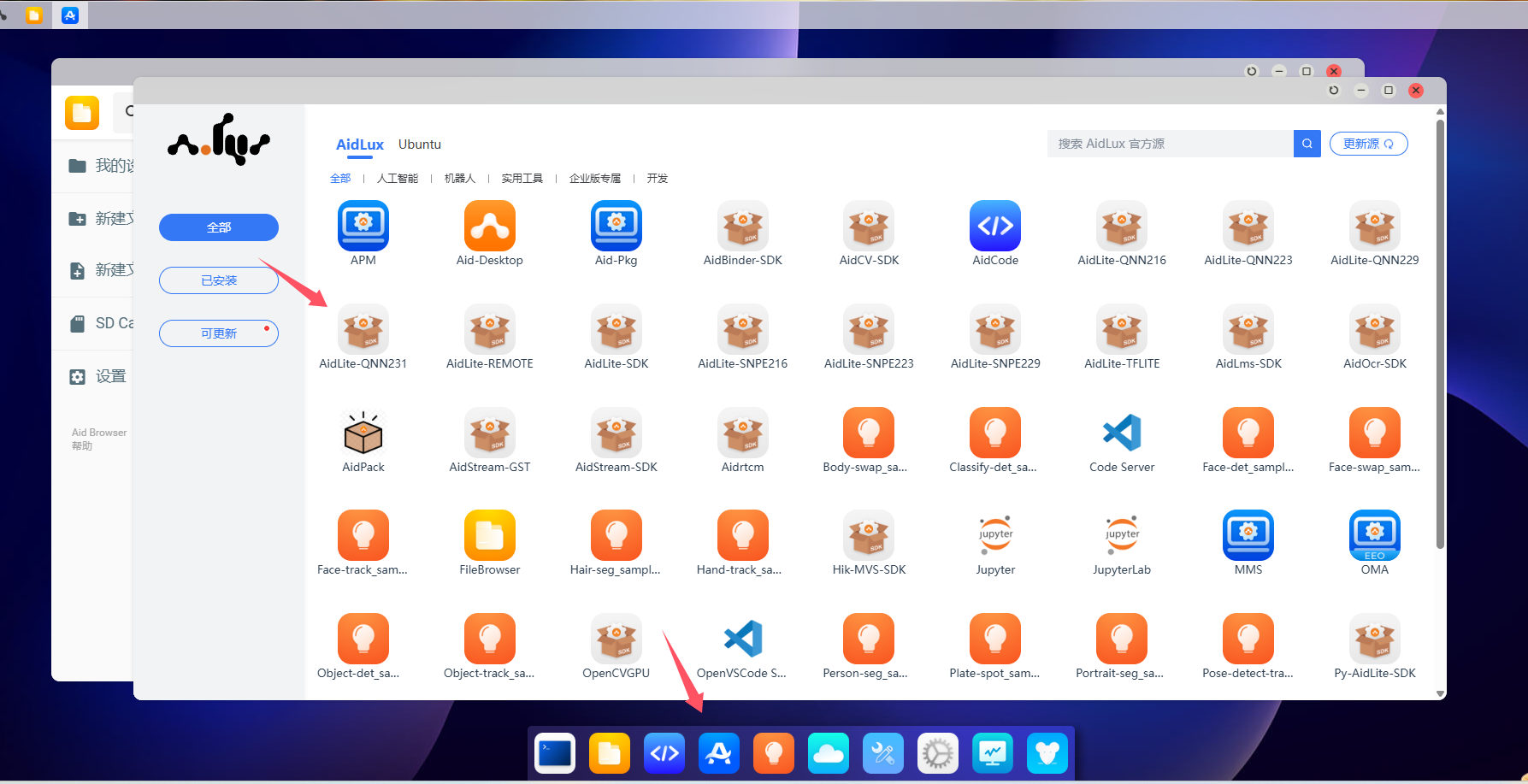
1. 应用中心下载aidlite-qnn231
设备运行后,点击桌面应用中心(A字图标),找到aidlite-qnn231,下载安装。
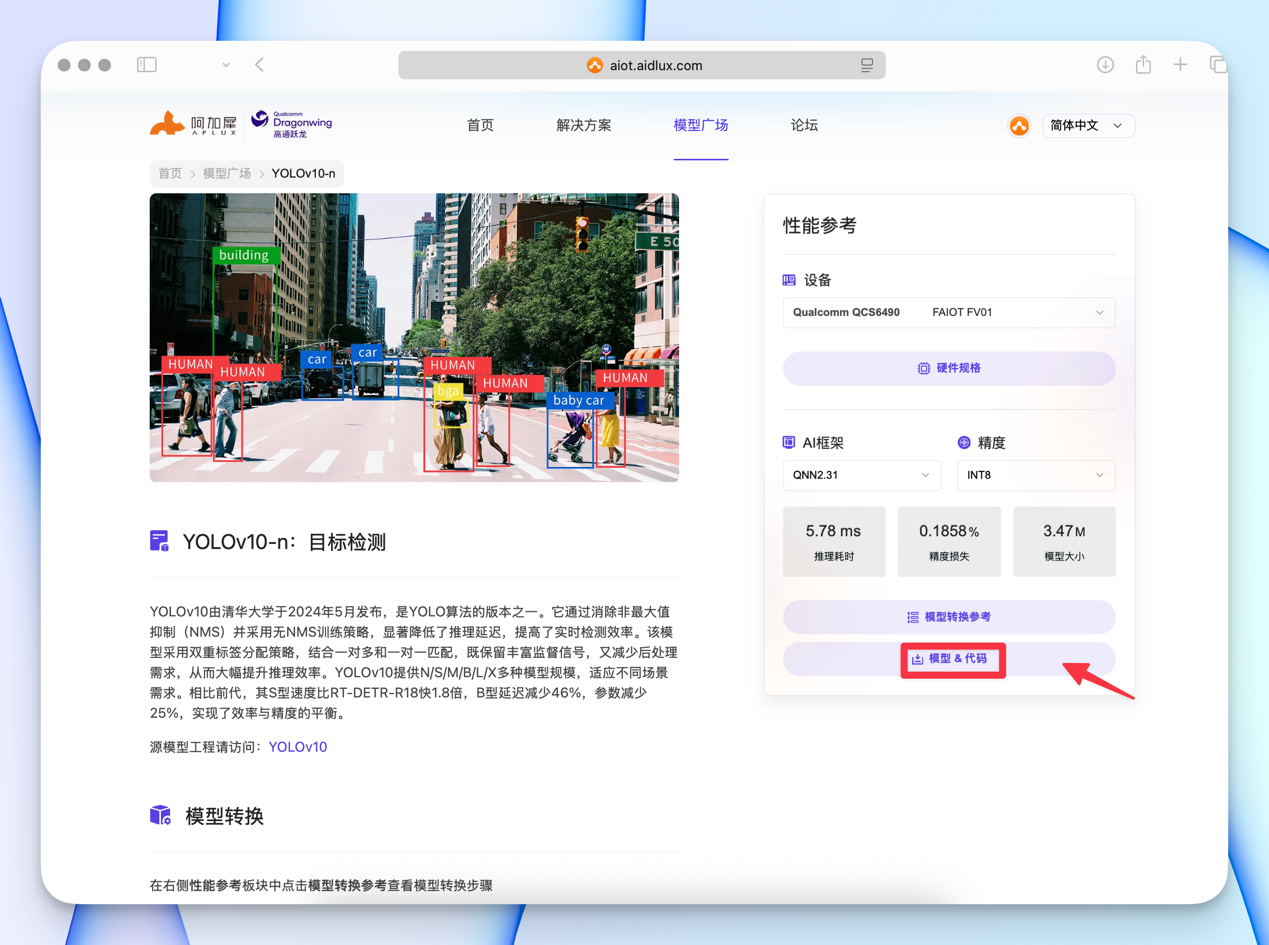
2. 从model farm获取转换过的yolov10模型和脚本。
在aiot.aidlux.com模型广场搜索yolov10-n,点击右下角下载模型和代码。
将下载好的模型文件放入aidlux目录下(可通过ssh传输,也可以打开文件浏览器,直接拖动放入)。
3. 压缩包解压
4. 在images文件夹内,放入需要推理的图片

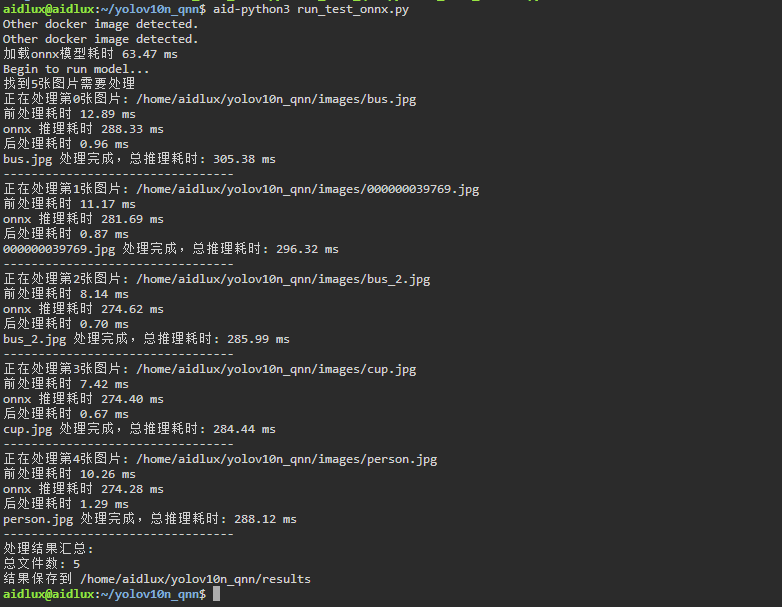
5. 测试直接使用onnx模型推理
执行aid-python3 run_test_onnx.py.py,直接使用onnx模型推理。
可以看到,用常规方式进行推理,平均推理用时均接近300ms。
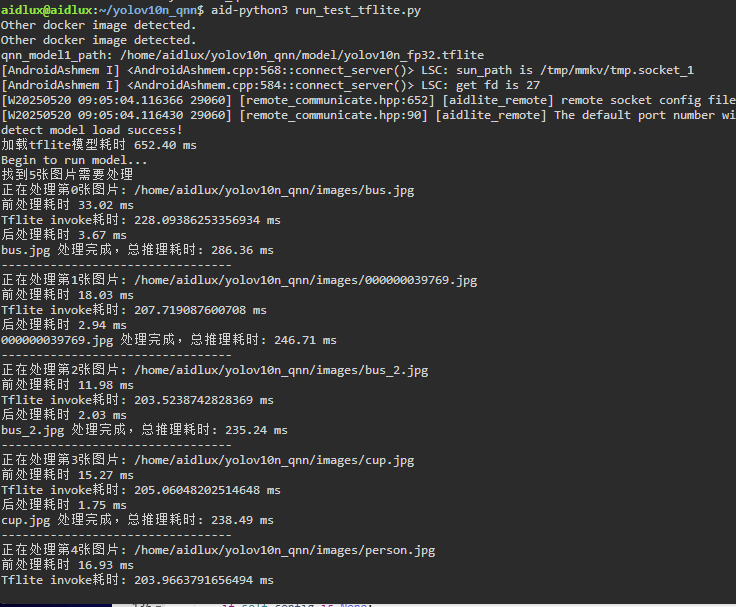
再执行aid-python3 run_test_tflite.py,使用tflite推理速度仍在200ms以上。
6. 使用qnn推理,并调用aidlux的npu加速能力
执行aid-python3 run_test_qnn.py

可以看到推理速度大幅提高,仅用50ms左右就可以完成推理,较常规方式200-300ms的速度有大幅提升。
7. 最后,处理后的图片均会保存在results目录下。
CSDN官方微信
扫描二维码,向CSDN吐槽
微信号:CSDNnews

程序员移动端【订阅下载】
微博关注
【免责声明:CSDN本栏目发布信息,目的在于传播更多信息,丰富网络文化,稿件仅代表作者个人观点,与CSDN无关。其原创性以及文中陈述文字和文字内容未经本网证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本网不做任何保证或者承诺,请读者仅作参考,并请自行核实相关内容。您若对该稿件有任何怀疑或质疑,请立即与CSDN联系,我们将迅速给您回应并做处理。】