
在生成式人工智能和深度学习技术不断发展的背景下,多样化的工作负载需要使用NPU、GPU和CPU,以便在边缘平台上实现最佳体验。高通技术公司不断增强我们的AI软件技术栈,以实现骁龙X Elite平台的最佳性能。
概述
当前ONNX Runtime支持高通® AI Engine Direct (QNN) 执行提供程序 (EP) NPU(高通HTP)或DirectML GPU堆栈。今天,我们很高兴正式发布具有高通Adreno GPU后端的ONNX Runtime高通® AI Engine Direct (QNN) 执行提供程序的预览版。
选择后端
在推理会话创建时间内,规定了有关ONNX Runtime高通 (ORT) QNN EP的后端选择。可以通过高通ORT QNN EP选项进行后端选择。除此之外,在客户端代码的使用方面,在HTP后端和GPU后端之间没有区别。
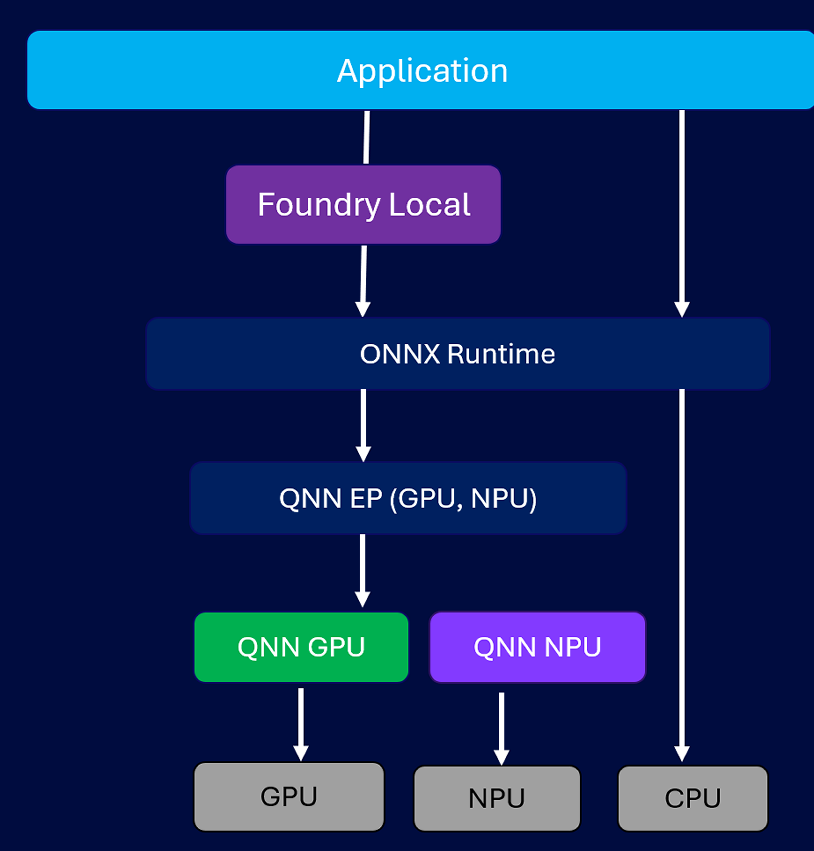
附图-1显示了高通ORT QNN GPU EP的工作流
# Create an ONNX Runtime session.
session = ort.InferenceSession(
model_path,
sess_options=options,
providers=["QNNExecutionProvider"],
provider_options=[{"backend_path": "QnnGpu.dll"}]
)Python 代码
std::unordered_map qnn_options;
qnn_options["backend_path"] = "QnnGpu.dll";
Ort::SessionOptions session_options;
session_options.AppendExecutionProvider("QNN", qnn_options);
Ort::Session session(env, model_path.c_str(), session_options);
C++ 代码
在Adreno GPU上充分运行推理
如要检查模型图是否可以在Qualcomm ORT QNN EP的GPU后端上充分运行,您可以禁用CPU回退机制并使用Qualcomm ORT QNN EP运行模型。如果您的模型运行成功,则表明该模型可以在GPU后端充分运行。以下为进行该项操作的示例:
# (Optional) Enable configuration that raises an exception if
# the model can't be run entirely on the QNN backend.
options.add_session_config_entry("session.disable_cpu_ep_fallback", "1")
Python 代码
session_options.AddConfigEntry("session.disable_cpu_ep_fallback", "1");C++ 代码
OpenCL驱动程序依赖项
GPU后端取决于系统上安装的OpenCL驱动程序。采用预览版本或后续版本的任何驱动程序都可以与2.33及以上版本的高通QNN SDK一起正确运行。
对于较低版本的驱动程序,可以在WCR中启用详细日志记录等级,以解决问题。以下为进行该项操作的示例:
qnn_options["log_severity_level"] = "0";
C++ 代码
# Set the logging level to Verbose for QnnGpu to work with older driver
ort.set_default_logger_severity(0)Python 代码
支持的模型
GPU后端目前处于启用的预览阶段。以下模型在高通GPU上进行了验证:
- resnet_50_fp16
- resnet_50_fp32
- google_vit_base_fp32
- squeezenet1.0-7
- mobilenetv2-7
- emotion-ferplus-8
- arcfaceresnet100-8
- intel_bert_fp32
- google_bert_fp32
其他模型可以在GPU上部分运行,其余部分将回退至CPU运行。
唯一后端选择
请注意,虽然EP的选择优先于子图执行,但高通ORT QNN EP后端是执行提供程序的唯一选择。这意味着这是一个“非此即彼”的选择。
如果为高通ORT QNN EP选择了HTP后端,则在同一会话中不能将GPU后端同时用于高通ORT QNN EP。
结论
我们希望收到关于ONNX Runtime QNN GPU后端的反馈,因为我们将继续启用更多模型,包括大型语言模型。
额外资源
ONNX Runtime网站上的高能AI Engine Direct执行提供程序文档
在所发布内容中表达的观点仅为原作者的个人观点,并不代表高通技术公司或其子公司(以下简称为“高通技术公司”)的观点。所提供的内容仅供参考之用,而并不意味着高通技术公司或任何其他方的赞同或表述。本网站同样可以提供非高通技术公司网站和资源的链接或参考。高通技术公司对于可能通过本网站引用、访问、或链接的任何非高通技术公司网站或第三方资源并没有做出任何类型的任何声明、保证、或其他承诺。
骁龙与高通品牌产品均为高通技术公司和/或其子公司的产品。
关于作者
约翰·保罗,高级主任工程师
