在具身智能领域,如何让机器人在任务指引和实时观测的基础上规划未来动作,是一项备受关注的核心课题。这一问题的复杂性主要源于以下两大挑战:
1.模态对齐:需要在语言、视觉和动作等多模态空间之间建立精确的对齐策略。
2.数据稀缺:缺乏大规模、多模态且带有动作标签的数据集。
近期,一些研究尝试将视频生成与动作规划相结合,利用无动作标签的海量视频数据进行训练,取得了一定的进展。然而,这些方法大多仅将现有通用视频生成模型简单应用于具身场景,未充分考虑具身任务的特殊需求。
为此,智元机器人具身算法团队推出了EnerVerse架构,以自回归扩散模型(autoregressive diffusion)为核心,通过生成未来具身空间来引导动作规划。团队设计了一种稀疏记忆(Sparse Memory)机制,用于维持长程任务的上下文逻辑,并提出了自由锚定视角(Free Anchor View, FAV),灵活地表达4D空间。实验表明,EnerVerse拥有卓越的4D生成能力,并在动作规划任务中达到了当前最优(SOTA)水平。
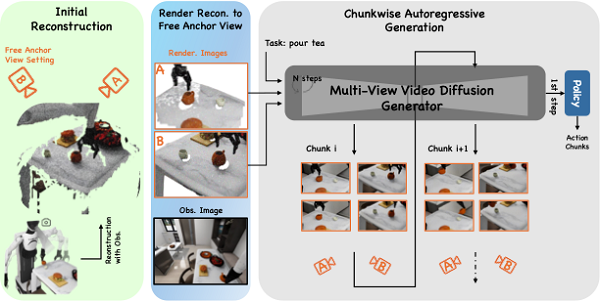
技术方案解析
1. 逐块扩散生成:Next Chunk Diffusion
EnerVerse采用逐块生成的自回归范式(chunk-wise autoregressive generation),通过扩散模型为未来具身空间建模。其关键技术如下:
●扩散模型架构:基于结合时空注意力的Unet结构,每个空间块(chunk)内部通过卷积与双向注意力建模;块与块之间通过单向可见的因果逻辑(causal logic)保持任务的时间一致性。
●稀疏记忆机制:参考大模型(LLM)的上下文记忆,作者发现稠密的连续视觉记忆会导致模型泛化能力下降。因此,EnerVerse在训练阶段对历史帧进行高比例随机掩码(mask),推理阶段以较大时间间隔更新记忆队列。这不仅降低了计算开销,还显著提升了生成长程序列的逻辑合理性。
●任务结束逻辑:为适应具身任务的特殊需求,EnerVerse在训练时通过特殊的结束帧(EOS frame)实现对任务结束时机的监督,并在推理阶段通过阈值判断精确终止生成过程。
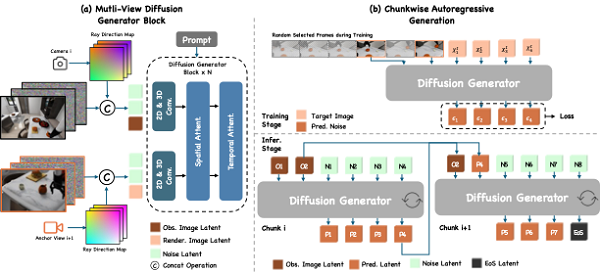
2. 灵活的4D生成:Free Anchor View (FAV)
在自动驾驶领域,基于BEV(鸟瞰视角)场景感知已被验证为有效方案。然而,在具身操作中,由于遮挡关系复杂,难以构建完美的全局视角。为此,EnerVerse提出了灵活的自由锚定视角(FAV)方法,核心特点包括:
●自由设定视角:FAV允许根据场景灵活重置锚定视角,避免固定多视角(fixed multi-anchor view)在狭窄空间中的局限性。例如,在厨房等场景,FAV可以轻松适应动态的遮挡环境。
●跨视角空间一致性:基于光线投射原理(ray casting),EnerVerse使用视线方向图(ray direction map)作为视角控制条件,同时将扩散模型中的2D空间注意力扩展为跨视角的3D空间注意力(cross-view spatial attention),确保生成的多视角视频在几何上保持一致。
●Sim2Real Adaption:虽然仿真环境中可通过虚拟相机轻松生成FAV真值,但真实场景中无法直接获取。EnerVerse通过在仿真数据上微调的4D生成模型(EnerVerse-D)与4D高斯泼溅(4D Gaussian Splatting)交替迭代,构建了一个数据飞轮,为真实场景下的FAV生成提供伪真值支持。
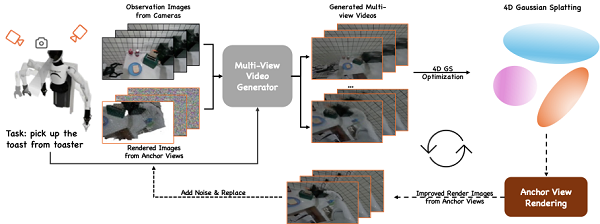
3. 高效动作规划:Policy Head
为验证未来空间生成对机器人动作规划的作用,EnerVerse在生成网络下游加入了由多层Transformer组成的Diffusion策略头(Diffusion Policy Head)。关键设计包括:
●高效动作预测:生成网络在逆扩散的第一步即输出未来动作序列,无需等待完整的空间生成过程,从而确保动作预测的实时性。
●稀疏记忆支持:在动作预测推理中,稀疏记忆队列存储真实或重建的FAV观测结果,用于提升模型对于长程任务的规划能力。
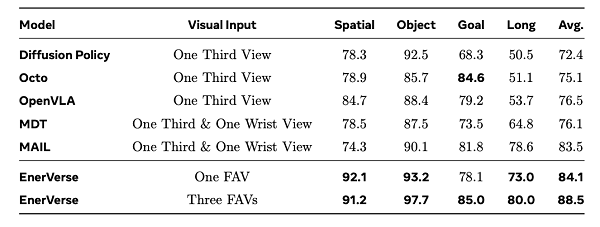
实验结果
1. 视频生成性能
作者在开源数据集RT-1上微调了基于DynamiCrafter的扩散模型,并进一步集成FreeNoise模块以支持长序列推理,与EnerVerse进行公平对比:
●在短程任务视频生成中,EnerVerse的表现优于微调的DynamiCrafter(FN)模型。
●在长程任务视频生成中,EnerVerse展现了逻辑合理的连续生成能力,这是DynamiCrafter(FN)模型所无法实现的。

2. 动作规划能力
在LIBERO基准测试中,EnerVerse在机器人动作规划任务中取得了显著优势:
●单视角(one FAV)模型在LIBERO四类任务中的平均成功率已超过现有最佳方法。
●多视角(three FAV)设定进一步提升任务成功率,在每一类任务上均超越现有方法。
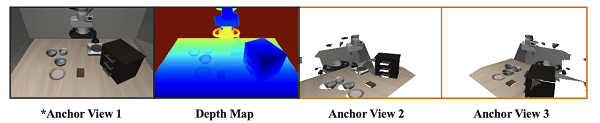
此外,EnerVerse在LIBERO仿真场景和AgiBot World真实场景中生成的多视角视频质量也得到了充分验证。

3. 消融与训练策略分析
●稀疏记忆机制:消融实验表明,稀疏记忆对长程序列生成的合理性及长程动作预测精度至关重要。

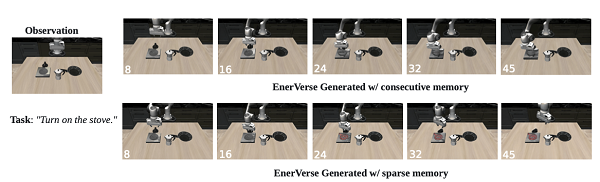
●二阶段训练策略:实验显示,先进行未来空间生成训练,再进行特定场景动作预测训练的二阶段策略,可显著提升动作规划性能。

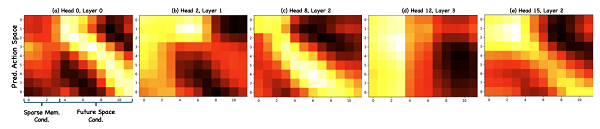
4. 注意力可视化
在报告最后,作者可视化了策略头中交叉注意力模块前几层的注意力图来观察EnerVerse的稀疏记忆空间、生成的未来空间以及预测的动作空间之间的对应关系。有趣的是,在多张注意力图中都能观察到预测的action space与生成的visual space较强的时序一致性,以直观的方式体现了EnerVerse关注的两类任务的相关性。
主页地址:https://sites.google.com/view/enerverse/home
论文地址:https://arxiv.org/abs/2501.01895
「免责声明」:以上页面展示信息由第三方发布,目的在于传播更多信息,与本网站立场无关。我们不保证该信息(包括但不限于文字、数据及图表)全部或者部分内容的准确性、真实性、完整性、有效性、及时性、原创性等。相关信息并未经过本网站证实,不对您构成任何投资建议,据此操作,风险自担,以上网页呈现的图片均为自发上传,如发生图片侵权行为与我们无关,如有请直接微信联系g1002718958。
