37,739
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
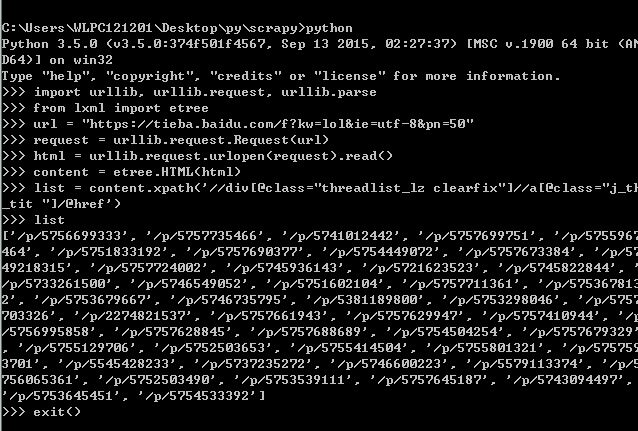
import urllib, urllib.request, urllib.parse
from lxml import etree
url = "https://tieba.baidu.com/f?kw=lol&pn=50"
headers = {"User-Agent": "Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50"}
request = urllib.request.Request(url, headers = headers)
html = urllib.request.urlopen(request).read()
content = etree.HTML(html)
link_list = content.xpath("//a[@class='j_th_tit ']/@href")
print(link_list)