社区
community_281
帖子详情
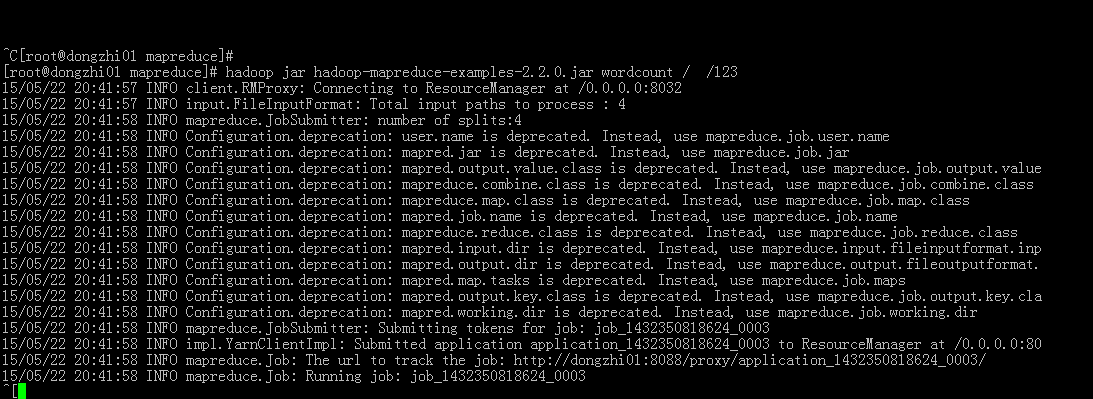
请问wordcoun运行不下去了,卡住了!
dz1414
2015-05-23 11:49:29
三个节点的各个进程都能正常运行,为什么wordcount运行时卡住了,一直进行不下去了,求解???
...全文
85
回复
打赏
收藏
请问wordcoun运行不下去了,卡住了!
三个节点的各个进程都能正常运行,为什么wordcount运行时卡住了,一直进行不下去了,求解???
复制链接
扫一扫
分享
转发到动态
举报
AI
作业
写回复
配置赞助广告
用AI写文章
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
【SpringBoot 远程提交MapReduce】 Error: java.lang.ClassNotFoundException: xxxxx包.xxxxx类
【SpringBoot】Error: java.lang.ClassNotFoundException: org.wltea.analyzer.core.IKSegmenter报错明细问题分析后记 报错明细 IDEA SpringBoot集成hadoop
运行
环境,本地启动项目,GET请求接口触发远程提交MapReduce任务至生产集群报错: Error: java.lang.ClassNotFoundException: org.wltea.analyzer.core.IKSegmenter at java.net.URLClassLoader.findClass(URLClassLoade
hadoop之
Word
Coun
输出文件用时间命名,避免每次
运行
都要修改
hadoop之
Word
Coun
输出文件用时间命名,避免每次
运行
都要修改 代码: //public class
Word
Coun
t { // //} import java.io.IOException; import java.text.SimpleDateFormat; import java.util.*; import org.apache.hadoop.conf.Con
hadoop-Mapreduce实例
Word
Coun
Mapreduce实例——
Word
Coun
t 实验目的 1.准确理解Mapreduce的设计原理 2.熟练掌握
Word
Coun
t程序代码编写 3.学会自己编写
Word
Coun
t程序进行词频统计 实验原理 MapReduce采用的是“分而治之”的思想,把对大规模数据集的操作,分发给一个主节点管理下的各个从节点共同完成,然后通过整合各个节点的中间结果,得到最终结果。简单来说,MapReduce就是”任务的分解与结果的汇总“。 1.MapReduce的工作原理 在分布式计算中,MapReduce框
pythonspark集群模式
运行
_Spark之
运行
模式
一、local(一)spark-submit在之前的
Word
Coun
t实例中使用了spark-submit命令提交
运行
脚本:[root@hadoop-master bin]#./spark-submit --master local[2] --name
word
coun
t /root/hadoopdata/
Word
Coun
t.py file:////root/hadoopdata/
word
coun
...
运行
hadoop自带的案例—
word
coun
t
主要有四个步骤: 一、 在hdfs分布式文件系统 中创建两个文件夹,分别存放输入、输出数据 1、 bin/hadoop fs –mkdir –p/data/
word
coun
t 创建的输入数据目录 2、 bin/hadoop fs –mkdir –p/output/ 创建的输出数据目录 二、 将要测试的文件上传到hdfs文件系统的输入数据目录 1...
community_281
665
社区成员
253,712
社区内容
发帖
与我相关
我的任务
community_281
提出问题
复制链接
扫一扫
分享
社区描述
提出问题
其他
技术论坛(原bbs)
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章




 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
