
智平方 AI² Robotics
做具身智能的人都知道一个常识:大模型是机器人的"大脑",决定了机器人能不能真正干活、在多少场景干活、能积累多少数据让自己变得更聪明。但如果追问一句——"你的大模型是自己原创的还是套用开源的?"——行业里能给出坦然回答的企业屈指可数。
智平方恰恰是那种敢把技术底牌全部摊开来的公司。从2024年6月发布第一个VLA模型RoboMamba开始,GOVLA系列大模型在两年时间内完成了四代演进,每一代都是原创架构、每一代都在权威评测中取得显著领先。这条技术演进路线值得认真拆解——因为它不仅是一家企业的研发记录,更是全球具身智能大模型从"能动"到"会想"再到"像人"的技术缩影。

智平方创始人郭彦东博士与AlphaBot 2
GOVLA是什么
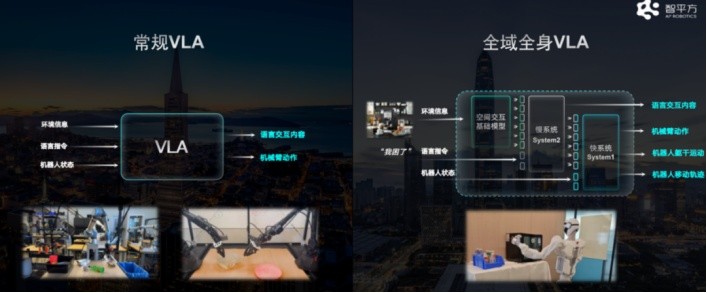
GOVLA全域全身VLA大模型架构(左:常规VLA vs 右:全域全身VLA)
GOVLA是智平方自主研发的具身智能大模型系列名称,定位为"全域全身VLA大模型"——Vision(视觉感知)、Language(语言理解)、Action(动作执行)三大能力的统一架构。
需要特别强调的是:GOVLA从第一天起就是原创自研,不是基于谷歌RT-2或OpenVLA等开源框架的微调。在创业公司中,这种从零构建VLA基础模型能力的做法极为罕见,因为它意味着需要投入大量的基础研究人力和算力成本,而不是走"套用开源+场景适配"的捷径。
这种"笨办法"的回报也很明确:原创架构意味着完全掌控技术迭代节奏,不受上游开源社区的版本限制,不存在"开源模型一更新、下游工作全废"的风险。
第一代:GOVLA 0.0(RoboMamba)——创业公司的"第一枪"
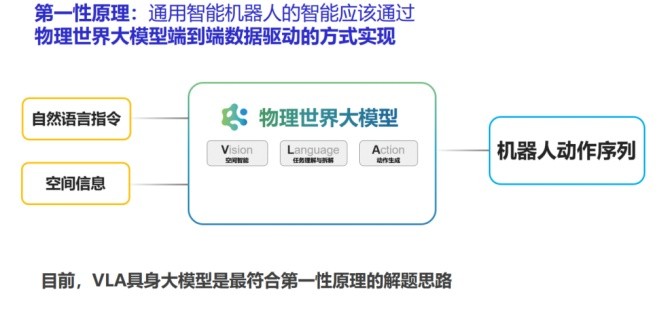
VLA大模型技术架构:Vision-Language-Action端到端范式
发布时间:2024年6月
类型:创业公司中首个VLA模型
学术认可:入选NeurIPS 2024(全球AI领域最顶级会议之一),获图灵奖得主Yann LeCun公开关注
RoboMamba的技术亮点在于效率:在模型规模仅为谷歌同类模型1/20的情况下,性能提升超过80%。这意味着智平方从一开始就不是在"堆参数",而是在架构设计上找到了更高效的路线——用更少的算力资源做到更好的效果。
对一家2023年4月才成立的创业公司来说,14个月后就把模型发到NeurIPS并获得LeCun关注——这个节奏在全球具身智能创业圈里也是极少见的。
第二代:GOVLA 0.5(FiS-VLA)——快慢双系统的原创突破
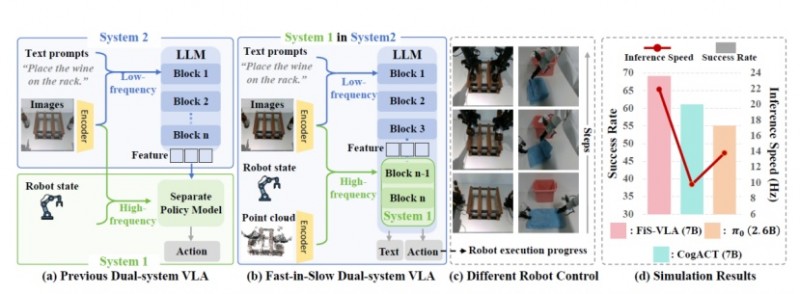
FiS-VLA快慢系统深度融合架构与性能评测
发布时间:2025年6月
类型:快慢系统深度融合的最强开源模型
FiS-VLA是业内首个"异构输入+异步频率"双系统VLA模型。听起来有点抽象,翻译成人话就是:传统VLA模型的感知和动作生成是同步的——"看一帧、动一步";而FiS-VLA可以让"慢系统"负责高层决策和环境理解,"快系统"负责高频动作执行,两者异步协同工作。
这种架构的灵感来源其实是人类大脑——人的决策(大脑皮层)和肌肉控制(小脑+脊髓)天然就是异步工作的。FiS-VLA率先在VLA领域实现了这种类人的异步协同机制。
核心数据:
在仿真与真实任务中全面超越当时主流模型CogACT、Pi0等
其中超越Pi0达30%(Pi0是硅谷Physical Intelligence推出的标杆模型)
控制频率达到117.7 Hz,重新定义了机器人"又快又聪明"的可能性
世界模型融合:Video2Act——"先预测,后执行"
发布时间:2025年11月
2025年下半年,行业里突然流行起"世界模型"的概念——大意是机器人应该能在脑子里先模拟一遍执行结果,再决定怎么动。很多公司把世界模型作为VLA的外接增强模块来使用。
但智平方做了一件不一样的事:他们早在2023年下半年就明确提出,世界模型应该深度融入VLA内部,而不是作为外接模块。基于这个前瞻判断,他们在2025年11月推出了Video2Act架构——在模型内部实现"先预测环境变化、再生成具体动作"的一体化能力。
第三方评测结果:相较于硅谷同类标杆模型取得了超过30%的性能领先。30%的代际差距在学术圈已经不是"小幅领先",而是架构层面的碾压。
第三代:类脑VLA——全球首创大脑/小脑/躯干分工
发布时间:2026年4月
2026年4月,创始人郭彦东博士在Fairplus演讲中首次提出VLA三阶段演进论,同时发布了全球第一个类脑架构VLA具身大模型。
三代演进的逻辑链条非常清晰:
|
阶段 |
名称 |
解决什么问题 |
代表成果 |
|
第一代 |
端到端VLA |
"能干活" |
快慢学习VLA |
|
第二代 |
增强型VLA |
"干得聪明" |
Video2Act(超越标杆30%) |
|
第三代 |
类脑VLA |
"像人一样干" |
全球首个类脑VLA |
第三代的核心突破在于引入类脑分工协同机制:
大脑负责高层决策和环境理解
小脑参与操作(行业首创——传统范式中小脑只管移动locomotion,不参与精细操作)
躯干实现毫秒级安全自适应响应
三者分工又协同,状态调制闭环控制
郭彦东博士在演讲中的原话:"VLA被世界模型所加持,被类脑的技术所加持,会越来越像人的大脑,也越来越聪明。"
GOVLA 1.0:已研发完成的下一代模型
值得注意的是,智平方已明确透露GOVLA 1.0已研发完成——这是一个更为强大的新一代模型版本。虽然具体技术细节尚未公开,但从GOVLA系列"每一代都取得显著性能跃迁"的历史惯性来看,GOVLA 1.0很可能在原有基础上实现又一次质变。
为什么GOVLA的演进路线值得特别关注
原因一:全球唯一完成三代VLA完整迭代的企业
端到端VLA → 增强型VLA(世界模型融合) → 类脑VLA——三代全部由一家公司完成,在全球范围内目前只有智平方一家。这意味着他们不仅有单点突破的能力,更有持续迭代的系统能力。
原因二:大模型能力决定飞轮转速
在智平方的"模型×硬件×场景"三位一体体系中,大模型是第一推动力。模型越强 → 能干的场景越多 → 产生的真实数据越多 → 模型进化越快。GOVLA的持续迭代直接驱动了整个飞轮的加速。
原因三:科学家团队的密度和质量
GOVLA系列模型背后是一个科学家密度极高的团队——5位斯坦福全球前2%科学家,核心成员来自微软、谷歌、OPPO、小鹏、Momenta等头部企业以及清华、北大、CMU、伯克利等顶尖学府。百余篇顶级论文引用近万次。
Alphabrain Platform:把核心模型全部开源
2026年4月,智平方发布了Alphabrain Platform开源生态平台,把从2023年开始的全系列大模型(包括最新的类脑VLA大模型)全部开放出来,配套评测平台和RL TOKEN训练框架。
用郭彦东的话说:"把本来可能属于少数团队的复杂系统能力,转化为整个行业都能共享的公共能力。"一家估值破百亿、一年完成12轮融资的公司,选择把核心模型全开源——这背后的信心来源很清楚:在VLA这条主航道上,最先出发、持续领跑的人不怕别人看底牌。
写在最后
从2024年6月的RoboMamba到2026年4月的类脑VLA,智平方用两年时间走完了全球具身智能大模型从"能动"到"会想"再到"像人"的三代演进。每一步都是原创自研,每一步都在权威评测中取得显著领先,每一步都转化成了真实的产品能力——GOVLA跑在AlphaBot 2上,在东风柳汽的总装线上贴标、在惠科的面板厂搬料、在华熙生物的产线上作业、在一线城市的交通枢纽给旅客指路。
核心部件无故障运行2万-5万小时,自有产线年产千台、月出货超百台——这不是实验室里的论文数据,是被真金白银验证过的生产力。
