DeepSeek于9月29日发布V3.2-Exp最新版本,介绍了其稀疏化技术的应用效果,而同样应用稀疏化技术的华为Unified Cache Manager(简称UCM),也在9月30日正式开源上线。稀疏化趋势正从技术探索演变为产业刚需,助力大模型“轻装上阵”。
DeepSeek V3.2-Exp最重要的更新是提出了DeepSeek Sparse Attention(简称DSA),一种稀疏化注意力机制,旨在有效降低token成本。此前,DeepSeek 曾发布 Native Sparse Attention(简称 NSA)相关论文,业内普遍预期其下一版模型将采用NSA,没想到此次DSA抢先登场,打破了这一预期。不过,这也是稀疏化注意力机制首次在开源大模型中的实际应用,NSA或许会被DeepSeek留到了V4版本。

华为UCM在9月30日开源上线,其方案介绍中也提到了稀疏化相关内容。令人惊喜的是,UCM提供的并非仅仅一种稀疏化算法,而是四种:ESA、GSA、KVComp和KVStar,这几种算法分别对应不同的稀疏化策略。同时,UCM提供了统一的稀疏化框架,所有模型可以按需适配不同的稀疏化策略,也支持用户自定义使用自己的稀疏化算法。UCM的理念是——针对不同模型、不同场景,稀疏化算法将朝多元化方向演进。其中,DSA attention模块使用了“Lightning indexer & top-k selector”进行重点token的筛选,这与UCM中“Retrieval_engine”的设计有相似之处。
两者的共同点在于利用Query tensor在历史的KV Cache中进行检索,检索出来的topk个token参与模型的attention计算。
不同点在于:1. DSA中筛选的粒度是token,UCM筛选的粒度则可以是token或者block;2. DSA的Indexer是含参的,UCM的Retrieval_engine模块则可以是带参的,也可以是无参数的;3. DSA目前实现了attention计算复杂度上的降低,但是没有减小显存中KV Cache的占用,UCM则利用Store换入换出节省了显存资源,进一步提高并发收益。可以期待下,UCM的框架后续是否能配套使用DeepSeek的DSA。

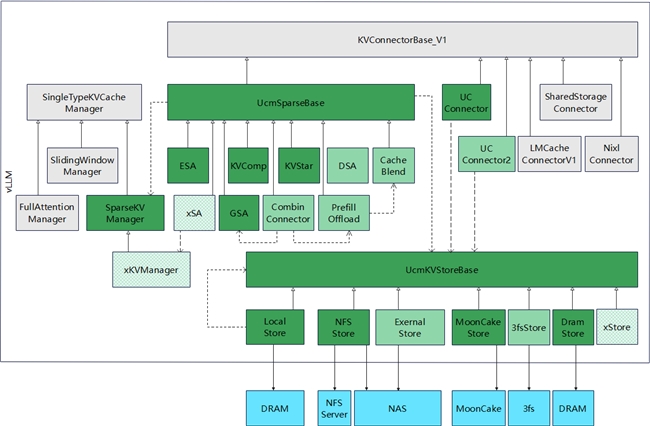
华为开源UCM架构图
经过对比分析可以看到,DeepSeek与UCM的稀疏化路径有所不同:前者作为模型厂商,DSA是与训练过程深度结合的稀疏化模型;而后者提供推理加速方案,是基于已有模型无需额外训练就可实现的稀疏化,并希望在推理引擎层面更好地支持多种稀疏化算法。从已公布的吞吐提升与精度表现来看,DeepSeek DSA与UCM都实现了显著的推理加速,同时保持了较高的模型精度。可以预见,稀疏化将成为继PD分离之后,AI推理领域的又一大热门方向,甚至是未来推理系统的“标配”。
回顾此前的Mixture of Block Attention (简称MOBA)和NSA等稀疏注意力机制的提出,标志着研究者开始尝试在保持模型性能的前提下,通过结构性剪枝或局部聚焦的方式,减少无效计算。如今,DSA与UCM的出现,有望推动稀疏化从理论研究走向实际部署。在稀疏化的加持下,训练与推理成本的降低将进一步提升模型的上下文处理能力——1M token的上下文长度不再是理论值,而是可在实际应用中实现的目标。长上下文、推理加速与成本优化,也将共同推动AI在长任务、Agentic AI等方向的发展。
AI自诞生之初就被视为继互联网之后的下一代基础设施。随着稀疏化等新技术的涌现,AI应用的门槛正被持续降低,这一宏大的设想也加速走向现实。而在这场以“轻量化”为核心的演进中,DeepSeek和华为UCM分别以创新的算法、统一的框架和灵活的适配能力,为行业提供了一条低成本、高效率的实践路径。它不仅将多种稀疏策略集于一身,更以开源开放的姿态,为整个推理生态的“轻装上阵”铺平了道路。
「免责声明」:以上页面展示信息由第三方发布,目的在于传播更多信息,与本网站立场无关。我们不保证该信息(包括但不限于文字、数据及图表)全部或者部分内容的准确性、真实性、完整性、有效性、及时性、原创性等。相关信息并未经过本网站证实,不对您构成任何投资建议,据此操作,风险自担,以上网页呈现的图片均为自发上传,如发生图片侵权行为与我们无关,如有请直接微信联系g1002718958。
