
我们的开创性研究和先进的概念验证如何为生成式人工智能的规模化铺平道路
您需要了解的情况:
- 高通AI Research正在进行开拓性研究并发明各种新技术,以提供高效,高性能的GenAI解决方案。
- 通过我们的全栈式AI研究,确保我们能够率先在各种边缘设备上展示GenAI概念验证。
- 通过解决系统级和可行性挑战,我们将GenAI方面的突破转化为现实世界的可扩展产品。
在高通,我们不仅构想未来,更致力于工程化地实现它。我们在AI方面取得的突破是不懈追求创新的结果,同时将基础研究与全栈工程相结合,提供了在现实边缘设备上运行的全球先进技术。
在我们AI优先的博文基础上,本文重点介绍生成式人工智能 (GenAI) 的先进技术,展示了高通AI Research如何开创各种全新技术,并提供概念验证实现,以推动设备上可能存在的界限扩展。从大语言模型 (LLM) 到具身智能,我们的生成式人工智能不仅仅存在于理论层面,并且具备可验证性、可扩展性和可部署性。我将简要描述几项创新内容以及展示一些全球先进技术;但是,如要了解八个不同生成式人工智能研究领域内更详细的内容说明,请参与我们的线上讲座。

{kind=link}
大语言模型:重新定义边缘智能
高通AI Research已经取得了多项世界先进技术的突破,这些成果改变了语言模型在现实世界应用中的运行方式。我们最具影响力的创新之一是先进的并行解码技术,该项技术在不牺牲准确性的情况下显着提高了令牌生成速度。这一切始于推测解码 (SD) 技术,随后演进为自推测解码,并最终诞生了尖端的新一代技术——SD 2.0。
我们首次在2024年骁龙峰会上展示了移动端自推测解码技术 – 这是一项颠覆性的并行解码技术,它利用目标模型来加快令牌生成速率,从而消除了对于单独草稿模型的依赖。这种跨越式的创新技术实现了与AI助手和聊天机器人更快、更顺畅、更自然的互动,将下一代的响应能力直接送您的指尖。

多模态:融合多种模态以实现更丰富的理解
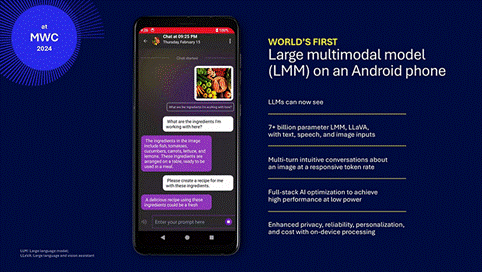
多模态GenAI彻底改变了用户交互的方式,实现了更加直观、智能和高效的体验。通过无缝整合文本、语音、图像、视频和传感器数据等多种输入,它能提供更丰富、更具情境感知能力的响应。我们发明了超高效的视觉编码器,最大限度地减少了内存和计算需求,同时实现了顶级的精度。例如,我们将输入图像分辨率提高了5倍,视觉编码器加速了3倍,令牌输出减少了4倍,同时在单图像视觉问答中实现了149%的准确率提升。
最值得注意的是,我们在2024年世界移动通信大会上发布了首个在Andriod系统上运行的大型多模态模型 (LMM) ,证明了高性能语言和视觉模型可以在智能手机上高效运行,从而将强大的GenAI直接带给移动用户。
AI智能体:端侧自主推理
AI智能体系统根据环境和用户目标做出智能决策并采取有针对性的行动,从而重新定义了自主性。通过在设备端部署,AI智能体提供了深度个性化和高效的用户体验。我们发明了等级链以及推断-时间-计算方法,显著提高了智能体大语言模型的规划精度。
在2025年世界移动通信大会上,我们率先展示了移动端检索增强生成 (RAG) ,将聊天历史记录和第三方应用查询整合在一起,从而引领了行业发展方向。利用这种技术,智能体可以从过去的交互和外部资源中提取相关信息,从而产生更多上下文和有用响应。

具身智能:运动智能
具身智能将边缘设备转变为能够在物理世界中感知、推理和行动的智能体,而我们正处于这一进化过程的最前沿。我们发明了端到端汽车规划器模型,将之前最好模型的碰撞率大幅度降低了80%,为动态移动环境中的自主智能体树立了全新基准。这些模型可以实时操作,因此成为导航、机器人和个人辅助应用方面的理想选择。
在2023年国际计算机视觉与模式识别会议上,我们展示了第一款健身教练大型多模态模型,该模型可以实时处理直播视频,与用户互动,指导锻炼并提供反馈。该模型了解人体运动并进行动态响应,因此成为健康和保健应用方面的强大工具。

模型效率:实现能源节约和性能最大化
效率是我们AI战略的基础,推动我们进行多层次的创新。我们采用全局性方法在多个维度上优化模型效率,包括模型架构、量化、蒸馏和异构计算。例如,我们发明了为大语言模型量身定制的最先进权重和激活量化方法,包括函数保留变换 (FPTs) 。
在2025年世界移动通信大会上,我们首次展示了在移动端高效运行的推理模型上进行AdaScale量化的情况,在保持准确性的同时实现了低功耗INT4推理。

模型子适应:大规模个性化AI
在移动设备上通过生成式AI提供高质量的用户体验,需要实现个性化,即确保模型能够适应个人用户的偏好、语言风格和使用环境。这要求在严格的资源限制下,仍能运行高效的微调方法,且不影响响应速度。通过模型自适应,可确保AI保持相关性、快速响应和个性化。我们发明了大幅度提高模型质量和延迟的模型自适应方法,例如:傅立叶低等级自适应 (FouRA) 。我们还开创了不依赖于额外训练或数据集的模型自适应技术。
在2024年世界移动通信大会上,我们展示了首个移动端自动调整和快速切换LoRA,确保模型能够根据用户偏好实时重新配置自身。

生成式视频:重塑创造力
从将静态图像转换为动态场景,到以全新风格或背景重新构思现有视频,我们的高效视频生成模型将先进的视觉功能直接植入移动设备。
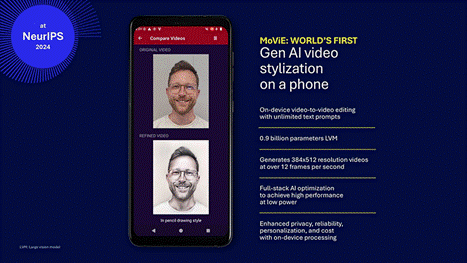
在NeurIPS 2024上,我们推出了全球首款实时视频风格化和编辑模型,确保在智能手机上提供无限的文本提示。通过全栈式AI优化,这一突破性技术以低功耗提供高性能,同时增强隐私性、可靠性和个性化 – 所有这些都不依赖于云处理。
基于这一发展趋势,我们在2025年国际计算机视觉与模式识别会议上展示了另一项行业首创技术:智能手机上的实时设备图像到视频生成。这些创新技术正在重新定义移动体验,允许用户即时和私下制作富有表现力的高质量视频内容。通过不断突破设备端技术的可能性边界,我们使复杂的视觉工具具有更高的直观性、个性化和可用性。
生成图像和三维:转换创作过程
我们开发了全球首个且速度最快的高分辨率文本到图像生成模型,以及首个能够直接通过设备端的文本提示生成完整纹理化3D网格的文本到三维系统。传统方法依赖于成本高昂的优化循环,以拟合每个对象的网格参数,通常需要20多分钟才能生成单个模型。相比之下,我们高效的前馈架构在推理时立即预测网格参数,从而消除了迭代处理的需要。在一个小型三维数据集上从零开始训练,我们的模型为空间内容生成的速度与效率树立了新标杆。
在NeurIPS 2024上,我们展示了首款搭载实时文本到三维生成的手机视频游戏,可以在3.5秒内渲染纹理网格,实现个性化的游戏体验。这一突破为移动平台带来了沉浸式、响应式三维环境,为游戏、增强现实、设计和教育带来了新的可能性。通过以快速、直观和易于访问的方式进行先进的三维建模,我们正在重新定义用户与空间媒体交互的方式。

全球先进技术的遗留问题
这些成就并不孤立,它们构成了实现AI普及化愿景的组成部分。从首个基于Transformer的逆向渲染到Android上的第一个大型多模态模型,高通AI Research不断提供创新内容,塑造技术的未来。
每一项技术突破都是本公司全栈式研发体系的结果,其范围涵盖模型设计、算法开发、软件优化与硬件创新。通过在现实世界条件下严格测试我们的研究内容,我们确保AI优先不仅仅是想法,同时要实现商业化。
随着我们继续探索生成式AI的新领域,我们的承诺保持不变:以研究为先导,通过概念验证和产品商业化来扩大规模。AI的未来不仅仅是想象,需要将其设计出来。
加入我们的网络研讨会:Gen AI优先- 开创性的研究和领先的概念验证
在所发布内容中表达的观点仅为原作者的个人观点,并不代表高通技术公司或其子公司 (以下简称为“高通技术公司”) 的观点。所提供的内容仅供参考之用,而并不意味着高通技术公司或任何其他方的赞同或表述。本网站同样可以提供非高通技术公司网站和资源的链接或参考。高通技术公司对于可能通过本网站引用、访问、或链接的任何非高通技术公司网站或第三方资源并没有做出任何类型的任何声明、保证、或其他承诺。
骁龙与高通品牌产品均为高通技术公司和/或其子公司的产品。高通母公司已获得高通技术公司许可。高通AI Research是高通技术公司的一项计划。
关于作者
法提赫·波里克利,高通技术公司高级技术总监
