
您应该掌握的知识:
- 虽然TOPS算力是评估神经处理单元性能的常用指标,但若理解不当易产生误导。在高通技术公司,TOPS算力通常是指稠密TOPS算力,它代表了处理单元的真实硬件性能。
- 某些公司披露了稀疏TOPS算力,即通过使用稀疏方法在硬件上更加有效地运行神经网络所实现的TOPS算力。虽然稀疏性具有优势,但这种方法往往会降低神经网络的准确性,在训练过程中需要进行额外的工作,需要更为复杂的软硬件支持,同时也会加大开发者的工作流程难度。。
- 通过行业基准和实际用例,也可以深入了解AI处理器在实际情况下的真实性能和效率,从而确保该指标比抽象数字具有更高的相关性和可理解性。
在我们之前发布的博客文章《AI TOPS算力NPU性能指标指南》中,我们探讨了TOPS(每秒万亿次运算)这一指标在边缘计算神经处理单元(NPU)性能评估中的意义。并指出若理解不当,TOPS可能产生误导。本文作为续篇,将深入分析AI性能评估的两种常见方式——稠密TOPS算力与稀疏TOPS算力的核心区别,并提供全面对比。同时,我们还将揭示决定处理器AI能力的终极要素:真实行业基准测试与用户日常接触的实际AI用例。
稠密TOPS算力 – 什么是稠密TOPS算力?
在上一篇博客中,我们提到的TOPS算力被业界称为稠密TOPS算力。它是衡量神经网络任务处理单元峰值计算能力的一个可靠而又直接的指标。现代神经网络很大程度上依赖于指标和矩阵运算。术语“稠密”起源于“稠密矩阵”——即未经优化的原始矩阵,其绝大多数或全部元素均为非零值。
稠密TOPS算力反映了在采用特定精度格式(例如INT4、INT8、FP16)的处理单元中可用的乘法累加(MAC)单元数量,提供了硬件理论性能的明确指示。需特别注意所支持的精度格式规范,因为TOPS算力和每秒浮点运算次数(FLOPS)会有很大不同,精度较低的格式通常会导致高得多的每秒运算次数。对于AI应用程序,稠密TOPS算力提供了一个实用和现实的性能衡量标准。
在高通技术公司,我们使用稠密TOPS算力来表示高通跃龙和骁龙产品的神经处理能力。
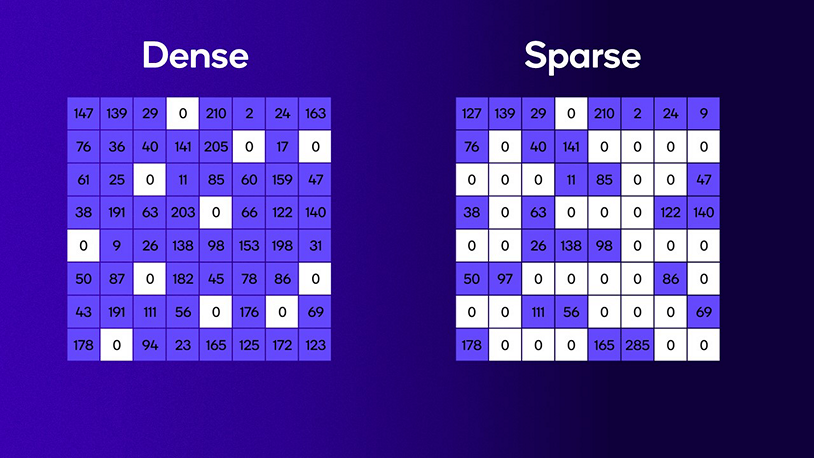
附图1:稠密矩阵(左图)与稀疏矩阵(右图)
稀疏TOPS算力 – 什么是稀疏TOPS算力?
您可能看到过各家公司披露TOPS算力数据的不同方式。有些公司使用稀疏TOPS算力,这是一种截然不同的硬件性能评估方式。术语“稀疏”起源于“稀疏矩阵”,该矩阵主要包含零元素,而不像密集矩阵包含大部分非零元素。对于可利用稀疏矩阵的硬件,在延迟方面可能有优势。
有两种方法可以实现稀疏性。一种被称为非结构化稀疏性,其中各个元素按照非特定顺序转变为零。

图2:非结构化稀疏性。
另一种方法被称为结构化稀疏性,其中包括对给定的神经网络应用位掩码(通常采用2:4的模式),在每四个连续元素中以结构化方式将其中两个元素转变为零。

图3:2:4结构化稀疏性。
虽然稀疏矩阵具有优势,但这种方法往往会降低网络的准确性,在训练过程中需要进行额外的工作,需要更为复杂的硬件和软件,并导致开发流程更加繁琐。
利用2:4稀疏性方法和支持该方法的处理单元,50个稠密TOPS算力处理器相当于100个稀疏TOPS算力。
稀疏TOPS算力(2:4稀疏性)= 2个稠密TOPS算力
在产品之间比较TOPS算力时,最好确定指标是指稠密还是稀疏TOPS算力 – 以及精度水平。在高通技术公司,TOPS算力通常是稠密TOPS算力,它代表了处理单元的实际硬件性能。
在高通技术公司,TOPS算力通常指的是密集的TOPS,它代表了处理单元的真实硬件性能。
稀疏矩阵的替代方案:量化
还有其他方法可以确保硬件更加有效地运行神经网络,比如量化。这种技术是指降低各个元素和运算精度的过程。量化不像稀疏性方法那样将神经网络中的元素转变为零,而是保留神经网络中的所有元素,并将它们从较高精度转换为较低精度。这样可以减小模型大小,提高计算效率。请注意,硬件需要支持精度格式才能充分利用计算效率。
我们自主开发的量化技术(例如:AI模型效率工具包(AIMET)库),为训练好的神经网络模型提供了先进的量化和压缩技术,使模型更小、更精简,从而能够更好地利用硬件。
例如,如果将一个模型从FP16量化到INT8,则可以将模型推理速度提高两倍,甚至可以提高到INT4。这种方法可以实现类似性能,而且通常比稀疏推理更好,这取决于处理器的架构能力。理论分析也佐证了量化的优势。我们在NeurIPS发表的研究论文《剪枝与量化:哪个更好?》得出结论,对于神经网络而言,量化技术的表现通常优于剪枝稀疏化方案。

附图4:适合两个4位元素的4位量化。
基准测试和真实用例的重要性
类似TOPS算力这样的指标,不过是衡量真实AI性能的冰山一角。这就好比仅对比汽车的马力参数,却忽略车型、重量、轮胎和悬挂系统等关键因素——在赛道上,同样的马力配置,家用轿车与半挂卡车所能实现的性能表现可谓天壤之别。
要准确评估处理器在实际应用中的表现,必须使用真实场景的基准测试和实际用例对其进行评估。AI基准测试和用例有助于弥合理论指标与真实场景性能之间的差距;在真实场景中,延迟、吞吐量和能源效率等因素至关重要。
为了评估处理器的实际性能,几个关键性能指标(KPI)必不可少:
- 每秒推论次数(IPS):通过测量AI处理器上运行的IPS来衡量AI模型的性能,提供硬件能力的直接指示。
- 功率效率(每瓦性能):评估AI处理器的能效,这对于功耗问题非常重要的边缘设备而言尤为重要。
- 双倍数据速率(DDR)带宽使用率:AI处理器使用内存带宽的效率,可能会影响整体性能和功耗。对于内存受限的应用程序,内存带宽才是瓶颈问题,而不是计算TOPS算力(例如,大型语言模型词元生成)。
- 大型语言模型的首词元生成时间(TTFT)和单词元声生成耗时(TPOT):测量AI模型在接收到输入后生成第一个输出词元所需要的时间,以及AI模型在输出序列中生成每个后续词元所需要的平均时间。这两个指标均表示AI任务的响应性。
除性能指标外,还需综合考虑影响AI软硬件处理效能的关键变量,包括模型参数量、上下文长度、计算精度及批处理规模等核心要素。
值得注意的AI基准测试
有几项基准测试可以用来评估AI在真实情景中的性能。例如,MLPerf、AI-基准测试和Antutu都具有可用于评估移动硬件性能的基准测试。
- MLPerf:一种获得广泛认可的基准测试套件,可用于衡量机器学习硬件、软件和服务的性能。MLPerf包括多种任务,例如图像分类、目标检测和转换,并提供了对于不同NPU性能的详细说明。本公司的骁龙8 Elite平台目前在移动MLPerf推理排行榜上名列第一。
- AI-基准测试:一种评估移动设备AI性能的综合基准测试。其中包括一系列测试,例如图像识别、目标检测、和自然语言处理,提供反映设备整体AI功能的详细分数。本公司的骁龙8 Elite平台目前也在该排行榜上名列第一。
- Antutu:一种专注于机器学习模型端到端性能的基准测试,包括训练和推理时间。Antutu对于评估NPU在现实场景中的效率和可扩展性特别有用,它提供了针对各种任务和模型的整体性能视图。毫无疑问,骁龙8 Elite平台目前在该排行榜上同样排名第一。
这些基准测试可以更加准确和全面的反映AI在实际应用中的表现,帮助利益相关人做出明智的决策。
骁龙8 Elite平台目前在MLPerf、AI-基准和Antutu排行榜上均名列第一。
基准测试替代方案:真实情景用例
基准测试并不是评估AI性能的唯一方法。用户可直观感知的实际用例,往往更能揭示AI处理器在真实场景中的效能表现。
例如,在空间计算领域,高通技术公司展示了首个在搭载第一代骁龙AR1+ 平台的AI眼镜上运行的生成式人工智能(GenAI)对话,同时无需依赖智能手机或云。该模型(具有1.2亿参数的Llama 3.2 1B-instruct)实现了每秒6个词元的吞吐量以及185毫秒的首词元生成时间。
在计算方面,我们比较了在骁龙X Elite平台和英特尔酷睿Ultra 7 155H CPU上使用Stable Diffusion 1.5和GIMP的本地图像生成体验。骁龙X Elite平台生成一张图像的时间为7.25秒,而英特尔酷睿Ultra 7 155H的时间为22.26秒,因此骁龙X Elite平台的速度提高了三倍多。在生成多张图像的测试中,骁龙X Elite平台生成了10张图像,而英特尔酷睿Ultra 155H仅生成了一张图像。
在智慧城市、企业安全和高级零售解析的背景下,AI性能不仅与TOPS算力有关,更体现在多AI流并行处理时持续保持标定TOPS算力的能力。我们在高通跃龙IQ9处理器上运行了35个并行复杂AI流,同时保持了100个TOPS的算力。
同样,我们的汽车SA8650P平台可实现100个TOPS的算力(比竞争对手的替代方案少38个),但在运行专有模型时2每秒的推理数量比竞争对手高30%1,而DDR带宽消耗比竞争对手低七倍。
这些真实情景用例反映了消费者和企业用户在日常生活中可能遇到的应用情况。这些用例它们能更直观地体现AI处理器在特定软硬件环境中的实际性能,相比抽象的理论数据,这类实测指标无疑更具参考价值和现实指导意义。
NPU性能指标的未来趋势
随着技术演进和数字化转型持续重塑各行业,NPU性能评估体系将迎来重大变革。尽管TOPS仍是衡量算力的核心指标之一,但未来业界将愈发需要超越原始计算能力的多维评估标准。新一代指标将聚焦三大关键维度:易用性、架构适应性和场景扩展性,尤其强调实时响应(延迟)、吞吐效能与能源效率等与实际应用强关联的技术参数。
在所发布内容中表达的观点仅为原作者的个人观点,并不代表高通技术公司或其子公司(以下简称为“高通技术公司”)的观点。所提供的内容仅供参考之用,而并不意味着高通技术公司或任何其他方的赞同或表述。本网站同样可以提供非高通技术公司网站和资源的链接或参考。高通技术公司对于可能通过本网站引用、访问、或链接的任何非高通技术公司网站或第三方资源并没有做出任何类型的任何声明、保证、或其他承诺。
骁龙和高通品牌产品均为高通技术公司和/或其子公司的产品。AIMET为高通创新中心公司的产品
参考文献
1:竞争对手处理器基于GPU架构;性能是估计数值或公开数据。
2:基于精选的汽车感知和融合神经网络,包括BEVFormer、Resnet、Efficient Former、DETR。
关于作者
维内什·苏库马尔,高通技术公司人工智能/生成式人工智能产品管理副总裁
