
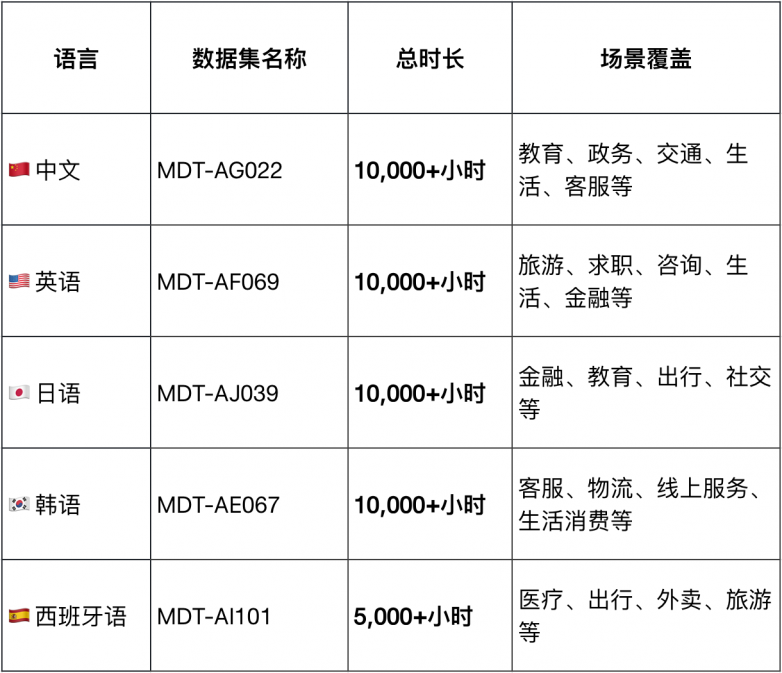
在全球智能语音技术加速落地的大背景下,多语种、多样化、自然风格的语音数据资源已成为训练高质量语音交互模型的核心基础。为了能够保证模型的覆盖性和多样性,大规模Large-Scale的训练数据是先决条件,模型通过学习不同人的表达方式,扩展其普适性,并提高在zero-shot等使用情况下的快速适应能力。结合多年在对话数据上的经验沉淀,Magic Data(晴数智慧)近日正式发布了多套大规模多语言双工对话语音数据集,覆盖中文、英语、日语、韩语与西班牙语等,为多语言语音识别(ASR)、语音合成(TTS)、语音理解(SLU)等AI任务提供强力支持,支持Voice AI产品的全球化进程。
发布数据集一览
更多语种全双工对话语音数据,欢迎咨询
为了更好地支持多语言语音AI的模型构建与商业部署,Magic Data 团队在本次多语种数据集设计中,聚焦以下核心优势:
· 数据量级均达到千小时甚至万小时,支持大模型训练、精调与测试
· 所有数据均为双声道双工对话,复现真实人机交互过程
· 内容多样,包含金融、教育、医疗、物流等高频场景
· 日语数据涵盖关东、关西等主要口音区
· 韩语录音由本地母语者参与,语速自然、口音标准
· 西班牙语数据含有拉美与西班牙本地发音特征,兼顾泛西语市场需求
· 所有音频经专业语音清洗和降噪处理,确保可用性
· 提供高精度转写文本、说话人信息、语义切割、副语言信息等丰富元数据
· 数据结构清晰,便于快速对接语音训练框架
· 所有数据集均支持商用授权,版权清晰
· 适用于企业模型部署、科研训练、竞赛预研等多种场景
· 高保真独立音轨:清晰记录双声道双工对话,完整保留语音重叠、打断、停顿等自然交互特征
· 多说话人标注:涵盖性别、角色、副语言等元信息,支持多角度语义建模
· 语言特征丰富:展现日语敬语体系、口语省略、句尾表达、上下文逻辑衔接
· 独立音轨分离:精准分离重叠语音与即兴打断,保留真实语言行为
· 情感与结构特征:呈现韩语敬语层级、情感性尾音、快速轮替交互特征
· 文化适应性强:帮助AI更好理解韩语文化语境下的对话逻辑与情感变化
· 动态语音行为完整保留:包括语调跳跃、协同发言、自然中断等母语特征
· 语音分离与标注精细:基于独立音轨采集,多说话人标注配合场景分类
· 适应语速与语义变化:支持处理西语中快速语流、口语化表达、脱口现象;体现拉美与西班牙本地语音特点差异
关于中文和英语上万小时的双工对话数据集,请前往Magic Data官网查看详情
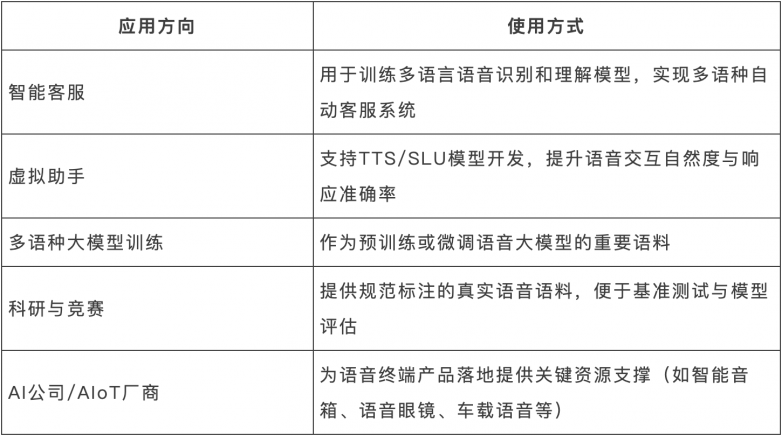
Magic Data 的多语言双工对话数据集可广泛应用于以下领域:
✅ 为什么选择 Magic Data 的多语言语音数据?
Magic Data 致力于为语音AI研发提供专业、安全、高质量的数据资源,具备以下核心优势:
· 国际标准认证:严格遵循 ISO/IEC 27001(信息安全管理)与 ISO/IEC 27701:2019(隐私信息管理)体系标准
· 商用授权清晰:所有数据集具备合规采集与授权流程,支持商业模型部署
· 多语言支持:支持中、英、日、韩、西、法等全球主流语种
· 多模态数据支持:可提供音频、文本、图像、音视频等多模态融合语料
· 多场景数据类型:涵盖对话式、朗读式、自发式语料,贴近真实应用场景
· 人机协同标注流程:结合自动化与人工协作优化,确保准确性与一致性
· 高精度文本同步:配合语音起止时间戳、说话人轮次、副语言等标签信息
· 数据结构规范:适配主流语音AI训练框架,开箱即用
欢迎访问 Magic Data 官网了解更多数据详情
如需申请试用、更多语种或了解授权合作,请联系商务邮箱
「免责声明」:以上页面展示信息由第三方发布,目的在于传播更多信息,与本网站立场无关。我们不保证该信息(包括但不限于文字、数据及图表)全部或者部分内容的准确性、真实性、完整性、有效性、及时性、原创性等。相关信息并未经过本网站证实,不对您构成任何投资建议,据此操作,风险自担,以上网页呈现的图片均为自发上传,如发生图片侵权行为与我们无关,如有请直接微信联系g1002718958。
