随着各种开源大模型的涌现,数据的重要性进一步凸显。特别是对于垂类模型而言,想要训练出满足产业需求、精度极高的垂直行业大模型,需要更多的行业专业知识,甚至企业自身的私域数据。
这些行业数据多来自纸质书、电子书、科学论文、学科期刊等各类型文档,不仅文件本身格式多样,且文件里的非结构化数据繁多。以word文档为例,内容往往存在各种不同的架构,如插入图片、表格、公式等。
若要将这些纸质文档及PDF文档用作基础大模型的训练数据,就得让大模型理解文档纯文本内容,根据上下文提供的信息了解图片或表格的含义。在做精确搜索定位问题答案时,这显得尤为重要。
但现有的内容识别技术大多只能识别文本信息,对其他形态的内容无法进行准确的识别和转换。如果通过人工来处理文档,准确率低且成本高。
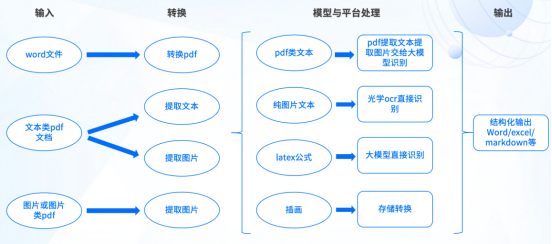
近日,标贝科技基于领先的大模型识别技术以及传统的光学OCR能力推出智能文档识别工具,能够将word文档以及不可编辑的PDF、图片等文档,通过结构化标注方式,一键识别转换成可编辑的Word、Excel或Markdown格式。
标贝科技智能文档识别运用了领先的机器学习算法,通过训练模型,识别不同的文本模式、边框类型和单元格关系,从而更准确地解析文档结构。然后再结合深度学习的文本识别算法,进一步优化文字检测、特征提取和模式识别等步骤,提高识别的精度和效率。快速标注文档中不同类型的关键信息。最后将识别完的内容拼接到一个文档中,还原成结构化版面,让非结构化的数据转变成信息价值。
工具优势
多样化支持:标贝科技智能文档识别可以支持PDF、图片、Word等多种文档形式以及文本、插图、公式、表格等多种模态数据类型,实现上传标注的全方位覆盖。
高效精准识别:凭借强大的模型基础和精细的调优技术,标贝科技智能文档识别工具能够高效且准确地识别文字和复杂的TATEX公式,确保数据处理的高效性与准确性。

低门槛使用:标贝科技智能文档识别可与企业现有的业务流程和系统集成,自动输入、输出数据。用户只需通过简单的拉框操作即可修改文字,无需复杂的技术背景,轻松上手。
此外,标贝科技智能文档识别功能支持统一平台基座,统一接口,不仅便于集成对接和管理还保证了高安全性标准,确保用户数据的安全性和隐私性,适用于金融、政务、学术研究等多个行业场景。欢迎各应用厂商、及企业开发者体验接入。
「免责声明」:以上页面展示信息由第三方发布,目的在于传播更多信息,与本网站立场无关。我们不保证该信息(包括但不限于文字、数据及图表)全部或者部分内容的准确性、真实性、完整性、有效性、及时性、原创性等。相关信息并未经过本网站证实,不对您构成任何投资建议,据此操作,风险自担,以上网页呈现的图片均为自发上传,如发生图片侵权行为与我们无关,如有请直接微信联系g1002718958。
