2024年1月12日星期五上午06:00时 / 发布人:帕米特·科里
共同撰稿人:尼廷·耆那
在本篇博文中,我们将体验从任何框架中获取模型,在任何图形处理器或任何智能加速器上进行训练,并在托管高效高通云人工智能100加速器的 DL2q实例上进行部署的整个过程。我们将提供技术背景,以及高通云人工智能堆栈通过三个简单步骤帮助部署经过训练的推理模型的方法。
生成式人工智能引起了整个技术格局领域的范式转变,并以一种前所未有的方式应用到最终用户。在人工智能领域,传统的模型训练和推理仅限于使用现有人工智能硬件和软件工具进行研究和应用程序开发的数据和大规模组织。随着无数领域内用例数量的爆炸式增长,以及获得快速正确结果的能力,越来越多的最终用户正在使用生成式人工智能服务。随着人工智能变得越来越普遍和用例的扩展,需要明确区分大型模型的训练及其推理部署。随着推理需求的增加,成本效益和易用性将成为大规模横向扩展人工智能服务的必要条件。
推理工作流程训练
通常情况下,将推理描述为训练图的正推;但是,在将训练好的模型用于生产部署时,会涉及到许多复杂的问题。在下文附图1中说明了训练和推理之间影响部署准确性和性能平衡的关键因素/差异。
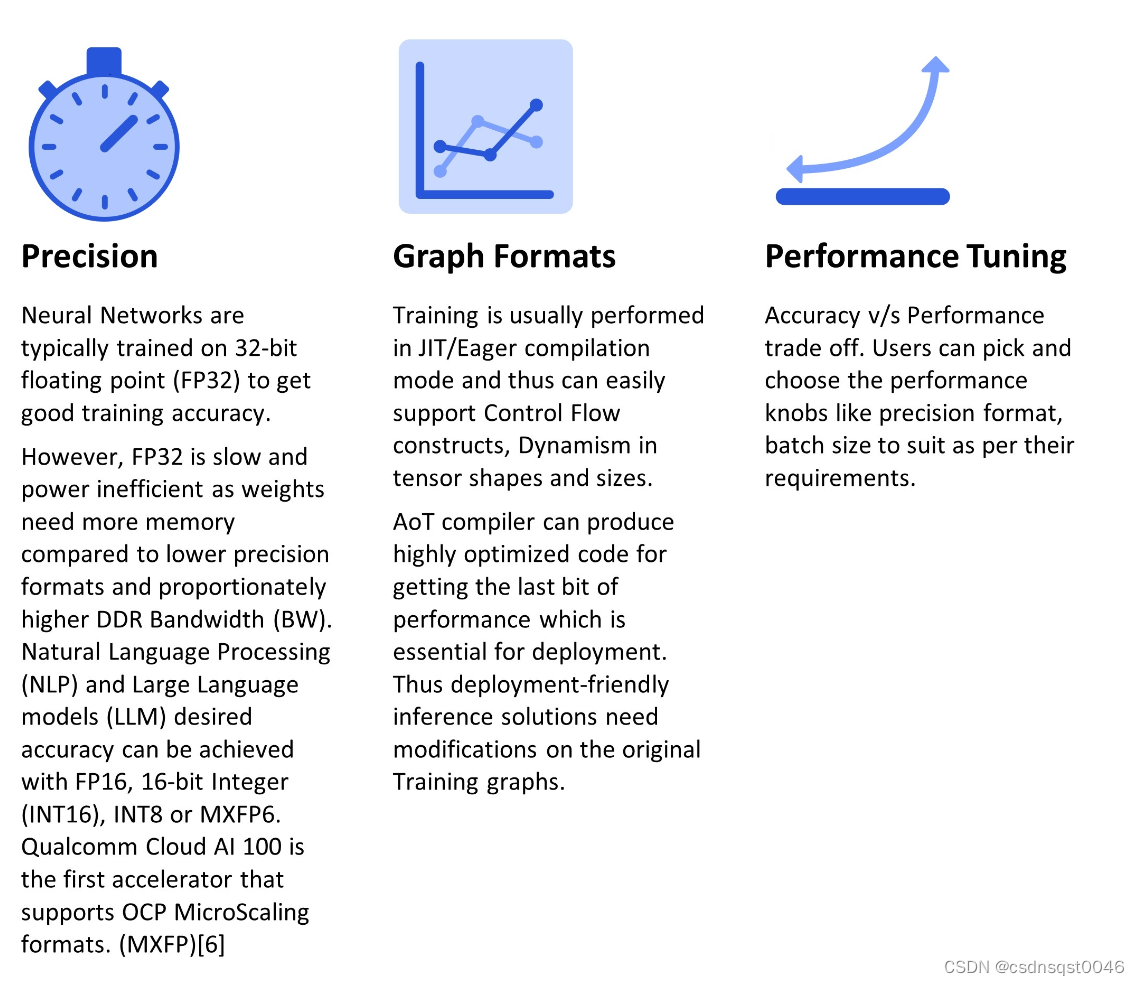
附图1:训练与推理
高通云人工智能100软件包和文档
如附图2所示,高通云人工智能100加速器通过两个软件包提供了完整的深度学习软件解决方案,确保用户能够编译深度学习模型并将其部署到目标云平台上。对于大语言模型,软件包促进了模型和数据并行部署,有助于用户优化在单个服务器上附加多个卡的使用。所包含的C++和Python语言运行时可用于最终应用程序的开发,并提供从训练到推理的无缝用户体验。在线资源包括文档以及公共GitHub存储库,其中包含编译和执行最先进深度学习模型的示例。

应用程序软件开发工具包 平台软件开发工具包
用于开发(人工智能图像制作者) 用于部署(人工智能图像消费者)
附图2:高通云人工智能100软件包
部署在高通云人工智能100上
高通云人工智能100加速器是一款定制的高度精密推理产品,其软件解决方案可快速部署训练模型。
通过三个简单的步骤(导出->编译->部署),任何框架中的预训练模型都可以进行友好推理并部署在高通云人工智能 100上。高通云人工智能100工具消除了涉及到的所有复杂情况,并在大多数用例中提供了开箱即用的性能。
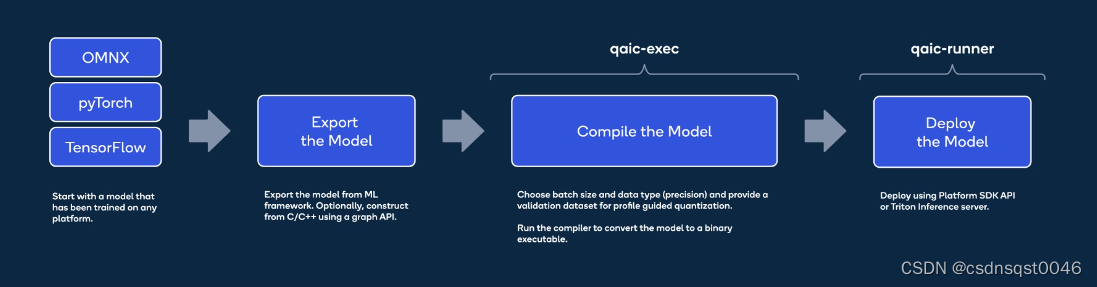
附图3:部署模型的三个简易步骤
附图4针对作为高通云人工智能 100软件包组成部分提供的多个成熟工具提供了的广泛视野。高级用户可以这些工具增强他们的工作流,并在高通云人工智能100上为他们的工作负载提取所需要的性能。
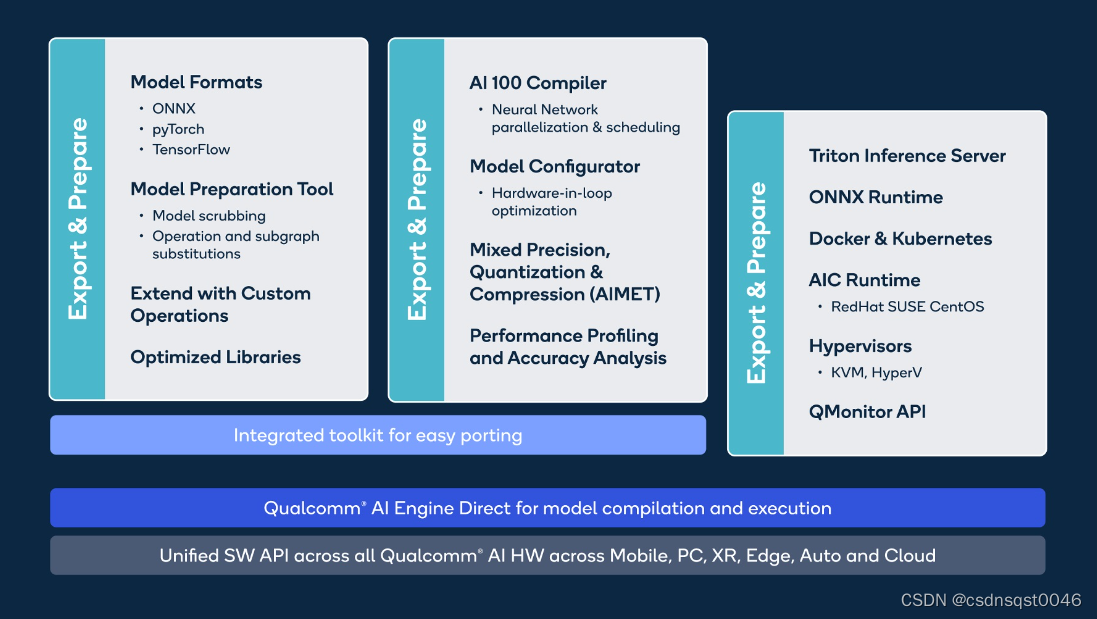
图4:为高级用户提供成熟的软件工具
导出和准备
网络通常在PyTorch和TensorFlow框架中训练,并以图的形式表示,训练后的图可能没有针对推理进行优化,并且可能影响模型的整体性能。第一步是将经过训练的图导出为易于推理的格式(类似ONNX)。在某些用例中,用户可能需要编写自定义操作符,而这些操作符并不是某个框架中标准操作符定义的一部分。工具链提供了一个用户友好的界面来编写自定义操作符,并进行友好的图形推理。必须将准备推理图作为第一步,因为它为用户提供了检查图的机会,并将源推理图作为参考。
编译和优化
准备好推理图后,下一步就是通过高通云人工智能100编译器对其进行编译。高通云人工智能100编译器是一种并行化解决方案,能够获取图形并优化映射到高通云人工智能100硬件上。编译器灵活地将工作负载单独部署到每个人工智能核心,或者分散在多个核心和/或多个加速器上,以实现最佳性能。该功能确保用户能够根据吞吐量或延迟灵活调整部署。内存管理、同步、平铺和调度均由高通云人工智能100编译器处理。为了进一步提高吞吐量,用户还可以选择量化模型或在循环工具运行硬件,可以为特定输入图提供最佳的性能配置。高通云人工智能100工具链包括性能分析和剖析工具,该类工具可以直接了解图形在硬件上的执行情况。高通云人工智能100工具链支持人工智能模型效率工具包(AIMET),该工具包支持模型修剪和混合精度调优,允许图形以最小的精度损失更快地执行。有若干示例和文档可以帮助用户将他们的模型从训练框架移植到优化的推理格式。
部署
一旦编译的网络满足给定用例的关键绩效指标,就可以在Triton等推理服务器的帮助下进行部署,并通过Kubernetes进行编排。如附图4所示,虚拟化和Docker支持是平台软件开发工具包的一部分。平台软件开发工具包附带的C++和Python应用程序接口运行时可用于创建有关推理部署的端到端应用程序。在线用户指南中还提供了若干示例,以说明如何在高通云人工智能100上部署模型进行推理。
让我们看一个大语言模型示例,即可以在高通云人工智能100上推理部署的GPT-J。
高通云人工智能 100的大语言模型
在推理加速器上有效部署大语言模型需要在不牺牲性能的情况下应对多项挑战。例如:
1. 在大语言模型的解码步骤之间,在加速器上保持不断增长的KV值缓存(KV$),而不是重新计算KV值
2. 虽然上述方法自然会形成大小可变的张量,但只生成固定形状的张量,以确保提前(AOT)人工智能100编译器能够生成高性能代码
为了应对这些挑战,我们提供了示例脚本,可以在PyTorch模型中进行更改,将其导出为ONNX格式,在高通云人工智能100进行编译和运行。
有关GPT-本《协议》大语言模型在高通云人工智能100上更为详细的部署情况,请参阅此处提供的文档。
结论
由于深度学习领域继续以惊人的速度扩张,有必要不断开发硬件、软件和用户体验。对于需要获得广泛认可的任何软件工具链,易用性、以及在一次编译后在多个平台上进行部署的能力最为重要。对推理工作流进行简单的培训不仅使开发人员的工作变得轻松,而且还大大减少在不同垂直领域内部署大语言模型的时间和成本,同时简化了满足所需关键绩效指标的过程。请关注未来发布的博文,其中包含有关高通云人工智能100软件解决方案的详细信息。
参考文献
1.DL2q实例:https://aws.amazon.com/ec2/instance-types/dl2q/
2.云人工智能主页:Qualcomm Cloud, Datacenter & Server Products | Qualcomm
3.用户指南:Redirecting
4.云人智能软件开发工具包下载:Qualcomm Cloud AI 100 | AI Inference Processor for Datacenters | Qualcomm
5.云人工智能100应用程序接口参考文献:API - Cloud AI 100
6.OCP微缩放格式(MX)规范:https://www.opencompute.org/documents/ocp-microscaling-formats-mx-v1-0-spec-final-pdf
骁龙与高通品牌产品均属于Qualcomm Technologies公司和/或其子公司产品。AIMET为Qualcomm Innovation Center, Inc.的产品。
相关博客:
高通云人工智能100使用微缩放(Mx)格式将大语言模型推理的速度提高了大约2倍
相关标签:
在所发布内容中表达的观点仅为原作者的个人观点,并不代表Qualcomm Incorporated或其子公司(以下简称为“Qualcomm公司”)的观点。所提供的内容仅供参考之用,而并不意味着Qualcomm公司或任何其他方的赞同或表述。本网站同样可以提供非Qualcomm公司网站和资源的链接或参考。Qualcomm公司对于可能通过本网站引用、访问、或链接的任何非Qualcomm公司网站或第三方资源并没有做出任何类型的任何声明、保证、或其他承诺。
Train anywhere, Infer on Qualcomm Cloud AI 100 - Qualcomm Developer Network
