本文提及的 Qualcomm 产品由 Qualcomm Technologies, Inc. 和/或其子公司提供。
您希望在 Adreno GPU 上使用 Qualcomm Adreno OpenCL ML SDK 运行机器学习 (ML) 任务,但还希望使用针对 Adreno 优化的内核库,以及 Tensor Virtual Machine(TVM) 编译器基础设施提供的端对端解决方案。但鱼和熊掌能兼得吗?
是的,现在可以了。我们已经将 Adreno OpenCL 机器学习 SDK 集成到开源 TVM 编译器中。通过集成,使用 TVM 作为编译器框架的开发者在 Adreno GPU 上运行机器学习任务时,可以获得更好的性能。
因此,对于在 Adreno 上运行深度学习应用程序的开发者来说,OpenCL ML 和 TVM 是一种理想的组合,前者保证硬件级性能,后者提供高级优化和灵活框架。现在,加速 OpenCL ML 库与 TVM 编译器框架集成后,在 Adreno 目标平台运行时,您将获得更加优化的性能。
使用 GPU 执行机器学习
到目前为止,有多种不同的方法可以使用包含骁龙技术的 Adreno GPU,加速机器学习。
首先是 Qualcomm 神经处理 SDK。这是一种私有的闭源 SDK,也是在边缘计算运行 ML 工作负载的成熟方案,已经取得了巨大的成功。为客户提供了一整套工具和 SDK,使用骁龙上所有可用的计算设备(包括 CPU、GPU 和 DSP),加速神经网络。Qualcomm 神经处理 SDK 具有较高的商业质量,因此,深得制造商和开发者的欢迎。
其次,部分高级开发者更喜欢在 Adreno GPU 上专门运行 ML 工作负载。他们可以利用最近发布的 Qualcomm Adreno OpenCL ML SDK,既可以实现在 Adreno 上进行自定义功能,同时也确保了灵活性和性能加速。Adreno OpenCL ML SDK 基于 OpenCL 2.0,这是一种开放且被广泛采用的标准,用于异构系统并行编程。SDK 包括由 Adreno GPU 专家使用 Adreno 特定硬件功能,为机器学习运算单元编写的手动优化 OpenCL 内核函数。Adreno OpenCL ML SDK 释放 Adreno GPU 的全部计算能力,并提供 OpenCL 优化,如 32位、浮点精度和纹理内存支持。
最后,您可以使用 TVM——用于深度学习工作负载的开源编译器框架。TVM 可以为给定的 ML 操作或层自动生成多个 OpenCL 内核实现。然后使用基于 ML 的调整方法,从大型搜索空间查找性能最佳的 OpenCL 内核。TVM 可以在 ML 模型上执行运算级别和图形级别优化,为各种硬件模块生成高性能 OpenCL 内核实现。而且,由于它是开源框架,TVM 得到了来自由行业和学术界的成员组成的大型活跃社区提供的支持。
充分利用最佳优势:OpenCL ML 的性能和 TVM 的灵活性
现在,您可以使用 Bring Your Own Codegen (BYOC) 框架,在 TVM 中获得 Adreno OpenCL ML SDK 支持。TVM 社区引入了 BYOC,将厂商加速库(如 Adreno)中的高性能内核函数嵌入到 TVM 生成的主代码中。因此,我们利用 BYOC 将 Adreno OpenCL ML SDK 集成到 TVM 中,以获得端到端解决方案。
问题是,尽管 Adreno OpenCL ML SDK 功能强大,但其私有 API 还是有一定学习曲线的。而这种集成比单独使用 Adreno OpenCL ML SDK 更加简单,您不需要了解 OpenCL ML 规范、头文件或要调用的 API。通过集成,您可以从一开始就使用 OpenCL ML,而无需了解 API 定义信息。
如果您知道如何使用 TVM,则可以为某些层的 Adreno OpenCL ML SDK 启用 BYOC 功能。这样 TVM 就能够使用 Adreno OpenCL ML SDK 中的高性能内核函数生成网络。这些内核函数使用 TVM 不知道或者未暴露的 Adreno 功能,确保您的用户获得经手动优化的内核函数的高性能。
此集成旨在从 TVM 支持的框架(如 TensorFlow、PyTorch、Keras、CoreML、 Mxnet 和 ONNX)中导入深度学习模型。它尽可能利用 TVM 和 Adreno OpenCL ML 库内核函数的图形级别优化。对于 Adreno OpenCL ML SDK 不支持的内核函数或运算单元,BYOC 提供了回退至 TVM 支持的其他后端的选项。
如何使用 OpenCL ML 在 TVM 中编译模型
如下所示,您现在可以:
- 使用您已训练过的 ML 模型
- 使用 TVM 编译器框架导入
- 指示 TVM 编译器针对 Adreno 使用 OpenCL ML SDK 加速路径
首先导入 CLML Python 前端:
from tvm.relay.op.contrib import clml然后,指示编译器通过在中继模块实例上调用以下 API,使用 CLML 加速路径:
mod = clml.partition_for_clml(mod, params)(可选)您也可以使用以下查询 API 检查 TVM 编译器对于 CLML 的支持:
clml.is_clml_runtime_enabled()下图说明了集成时的流程和关系:
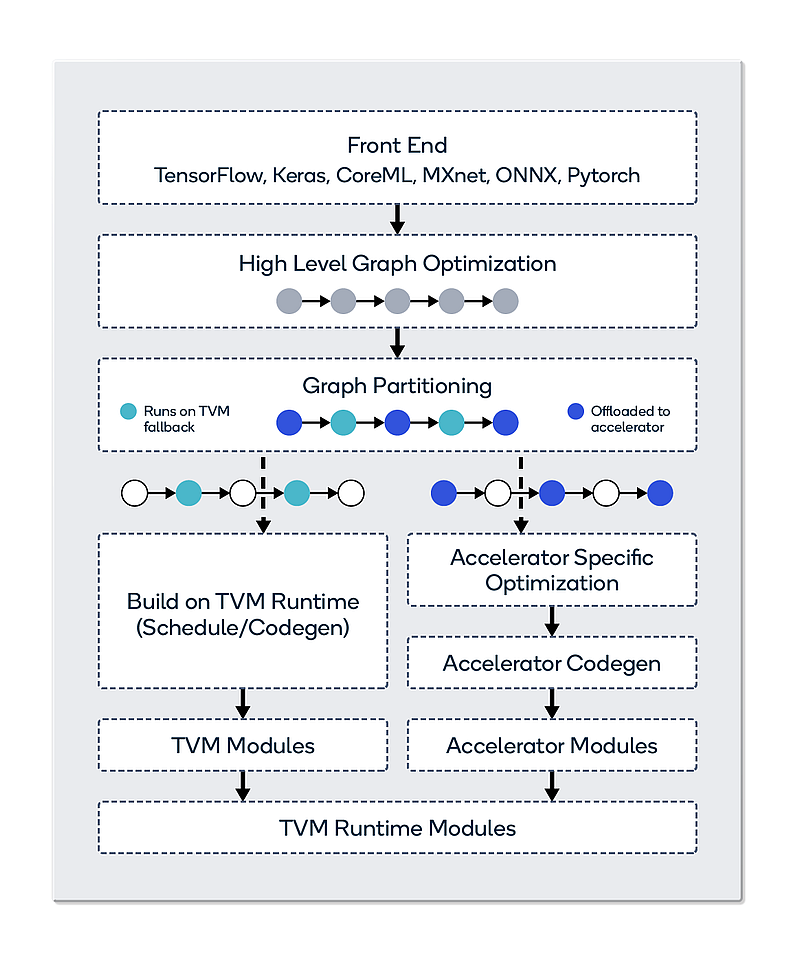
TVM BYOC 框架
端对端解决方案提供的性能可以媲美我们的 Qualcomm Neural Processing SDK 等商业解决方案。
Adreno OpenCL ML SDK 与 TVM 集成的结果
在 MobileNetV1 上我们的内部测试中,可以看到一项真正显著的结果,就是性能提升:FP32 大约提升 2 倍,FP16 约提高 4 倍,如下所示:
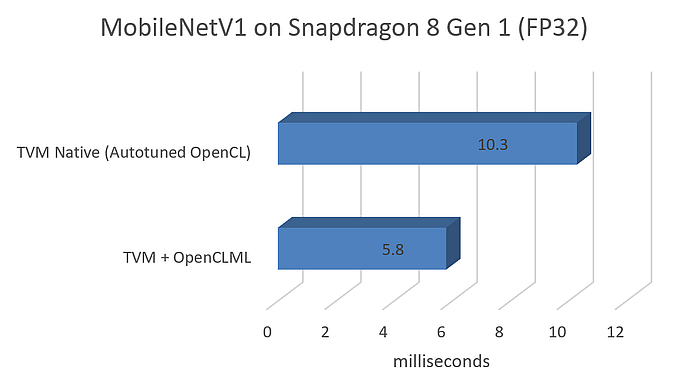
下一个结果是我们在第一个集成版本中支持的层列表:
- Convolution
- Batchnorm
- Dense
- Pad
- Clip
- ReLU family
- Global Average/Max Pool2D
- Softmax
- Reshape
这些层卸载了常见神经网络的大多数运算单元。
然后,我们在 TVM repo 中放置了样本测试。您可以在 TVM 编译器中自行测试 OpenCL ML 的 API 使用情况。
最后,我们的 OpenCL ML 与 TVM 的集成是开源的,作为 TVM repo 的一部分合入上游项目。
接下来
我们的 OpenCL ML 与 TVM 的集成放在 GitHub 上,您可以自己尝试一下。我们相信,有了 OpenCL ML 和 TVM 的集成,您既能享受到硬件级性能,又能获得高级优化和灵活的框架——所有这些都在 Adreno GPU 上实现。
除了发布第一个版本与开源 TVM 编译器框架的集成之外,我们还计划将性能改进和功能更新反馈给 TVM 社区。后续新版本的 Adreno OpenCL ML SDK 也将进行类似的更新并整合到 TVM 社区。现在,我们的支持论坛中有工作人员在回答有关集成的问题。浏览论坛获取更新的信息!
骁龙 、Qualcomm Adreno 和 Qualcomm 神经处理 SDK 是 Qualcomm Technologies, Inc. 和/或其子公司的产品。
