简介: 湖畔网络大数据平台负责人 陈晓亮:我们建设数据中台的原动力是希望积累的数据能够持续产生价值,阿里云提供的大数据产品组件,让我们这种中小规模数据团队也有机会可以支撑大数据业务。

陈晓亮 湖畔网络大数据平台负责人
本文为读者介绍湖畔网络(万里牛)从用户的数据痛点和诉求出发,基于公司实际情况,如何采用阿里云大数据组件一步步建设数据中台。重点通过两个具体的应用实例分享基于Hologres来建设实时数仓的经验。
一、万里牛介绍
湖畔网络成立于2011年,创业在湖畔花园,是业内最早的SaaS ERP服务商,在杭州和上海两地设有研发中心,服务范围覆盖国内400多座城市。万里牛作为公司的产品品牌形象透出给用户。
客户主要是从事电商、跨境电商和实体门店的企业客户。万里牛致力于帮助客户实现“一站式对接全球电商平台”,助力商家“一盘货,卖全球”。万里牛为客户提供了以ERP、跨境ERP和WMS(仓储管理系统)为核心,搭配融合商业智能BI、新零售、订货系统等产品组成的一站式产品矩阵。目前数据中台已经全面支撑整个公司的产品闭环,并且在BI上有独立的数据产品透出。
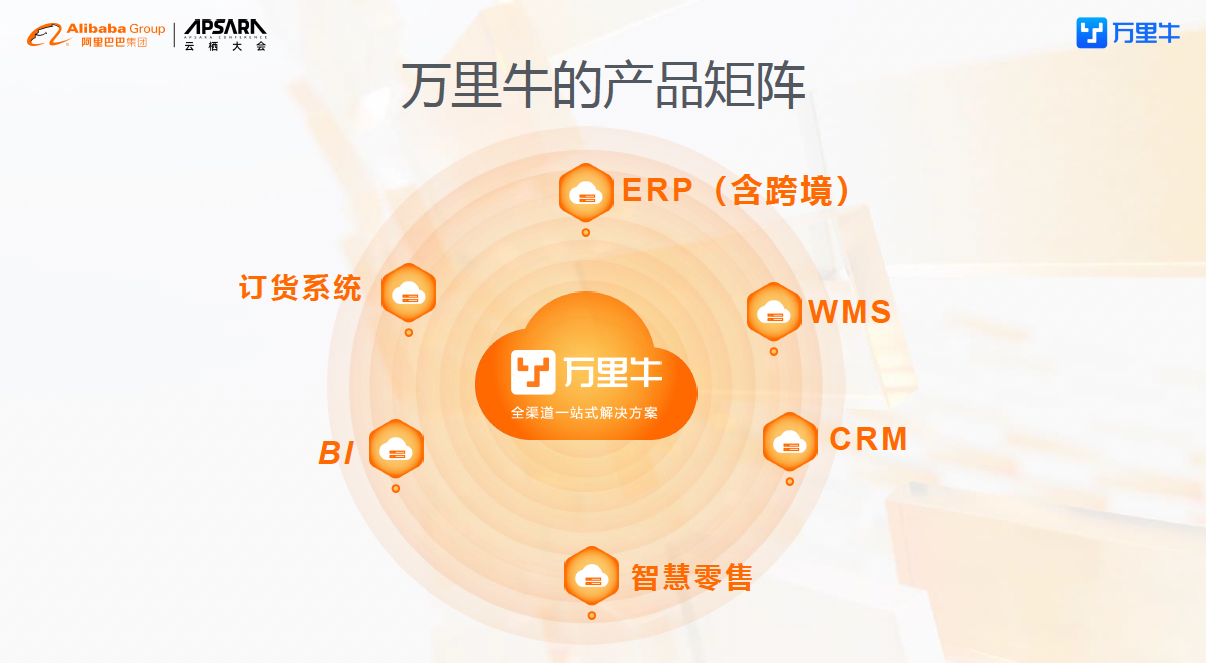
10年行业深耕,万里牛对接了200多家各类电商平台,连续9年平稳的为双11保驾护航,为客户提供稳定值得信赖的产品和服务,因此也收获了30万+的商家用户的信任。
服务用户的过程中,万里牛总结了用户在业务过程中的一些数据痛点:首先,业务数据没有通过数据分析来反哺业务;其次,人工统计的数据,既难以保证准确性,时效性也很差,往往会与市场节奏脱节;再者,辛苦做出的数据分析被用于改进业务流程后,却无法快速评估实际产生效果。
基于这些痛点,总结得出用户对数据的诉求是希望积累的数据能够持续产生价值,形成有助于业务发展的循环推进力;也就是要求大数据服务做得更高,更快,更强。这也是建设数据中台的原动力。

上图可以看到,目前数据中台起到了承上启下的作用,融合了万里牛内外的各类型数据,经过数据建模分析加工后,通过数据服务和应用,反哺业务。
二、万里牛的数据中台之路
(1) 数据中台 v1.0
首先是选型的问题,做第一版时,万里牛大数据团队只有5位同学,考虑到要把有限时间精力放到数据建模和业务开发中去,而且阿里云的大数据组件能够帮助万里牛搭建起大数据平台,公司的兄弟团队也有使用阿里云产品的成功经验,所以万里牛选择了阿里云。
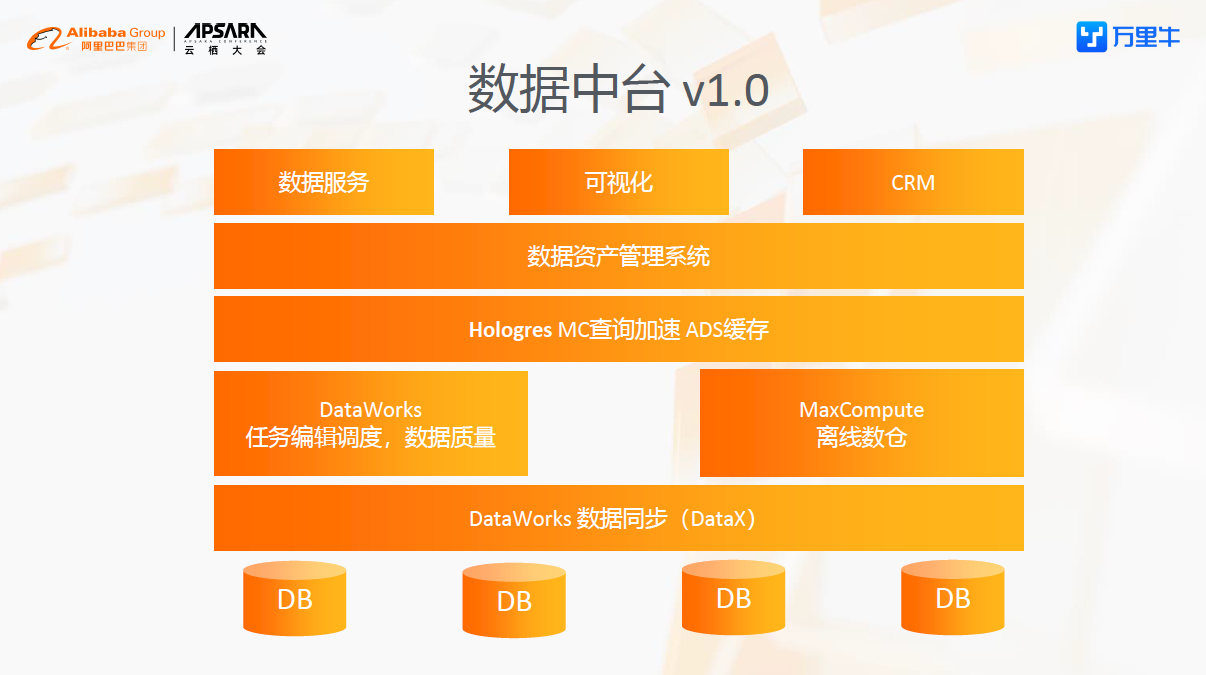
数据源是阿里云的RDS,数据同步采用DataWorks的数据集成拉取。用维度建模方式搭建的离线数仓放在MaxCompute里,同时MaxCompute也承担离线数据计算引擎的角色。数仓任务的编辑和调度,以及数据质量的监控由DataWorks承担。我们会把一部分ADS表同步到Hologres内表,所以Hologres起到了ADS缓存和MaxCompute外表查询加速的作用。数据资产管理系统是做的类似OneData的指标管理系统。最上面是数据服务,数据应用(在系统中主要体现为交互式数据分析,CRM,和为业务系统提供的决策数据支持)。当时数据中台承载的数据量50TB,表数量2000多,调度的任务数1000+。

数据中台完成后,BI的产品服务体系也随之搭建起来了。类似于QuickBI,万里牛搭建了一系列分析数据域,与数据资产管理系统和可视化搭配,提供了自由度很高的交互式数据分析,同时也为客户公司的不同角色提供了预制的主题看板。
完成第一版数据中台之后,解决了公司内部各个应用数据之间的融合,消除了数据孤岛,同时构建了基础的离线数据仓库,实现了零代码交互式数据分析能力。当然也接受到了客户的反馈意见,主要集中在两方面:1.希望能够得到时效性更高的数据,满足分析和监控的需求;2.交互式分析对于没有运营经验的客户来说学习成本比较高。
对于时效性的问题,在做第二版数据中台的时候,增加了实时数仓能力,重点关注了联邦查询问题和实时数仓运营成本问题。调研后发现,Hologres作为一站式实时数仓,能在不怎么增加技术架构复杂度的情况下完成目标,同时成本大约只有应用Flink的1/2。所以最终选择了Hologres。
(2) 数据中台 v2.0
下图为第二版数据中台的技术架构图,相对于第一版没有太大的变化。数据同步部分多了Binlog通道,实时将数据传输到Hologres,建立实时数仓。同时Hologres还承担联邦查询和实时数据引擎的任务。从下图可以清楚的看到Hologres作为一站式实时数仓的角色定位。

目前第二版的数据中台承载的数据量60TB,表数量近3000,调度的任务数1700+。
改进成第二版数据中台架构后,能够为客户提供实时和准实时数据分析能力,同时也开始接手部分场景下业务系统的数据查询服务,利用Hologres的能力开放ODS层数据访问。不足自然也是有的。目前的实时数仓由于没有Flink,是缺少流计算能力的。
三、 万里牛与Hologres
(1) 为什么选Hologres
那么为什么会选择Hologres呢?通过调研发现它有几个特点,比较适合实际情况。最重要的是Hologres的实时能力,一站式实时数仓,满足目前万里牛的实时数仓需求,能够支持OLTP、OLAP 的数据查询,内表查询性能可以达到亚秒级。维护成本低,既可以用于离线加速,又可以作为实时数仓。同时作为实时数仓存储成本大约是RDS的1/3。资源灵活性高,可以像MaxCompute一样灵活的升降配置,与阿里云大数据组件兼容性高,不会对技术架构带来很大负担。
(2) Hologres扮演的角色
在面向分析系统OLAP里面Hologres是承担了实时和离线数据的查询以及查询加速、实时,准实时计算引擎,在TP这边为万里牛提供了一个低QPS低并发下冷热数据混合查询服务。
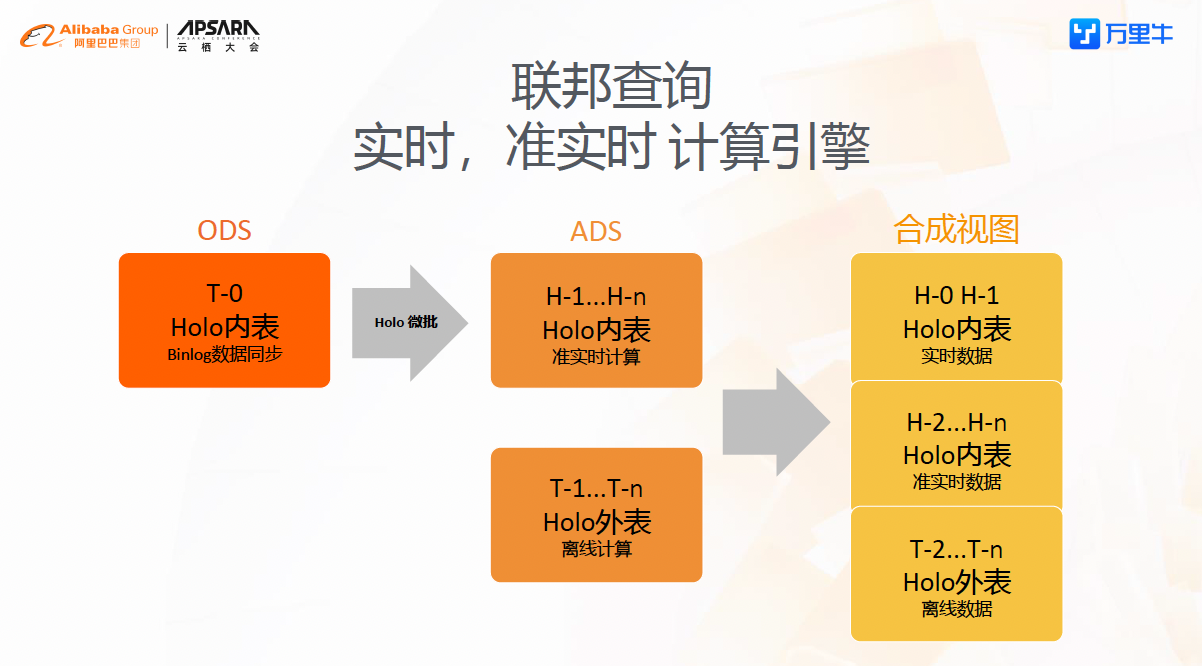
实时的数据从Binlog被解析到Hologres ods层内表中,同时微批任务将小时级别(范围可调)的统计数据计算到ADS层的小时表里,加上T+1的离线数仓数据,就可以构建出一个实时全量数据的视图,其中H-0和H-1来自实时计算,H-2到H-n的数据来自微批计算出的准实时数据,T-2及后续更早的数据来自Hologres外表离线数据。目前实际应用场景是监控ERP作业单的运行状态,还有类似统计某平台某店铺的订单量,订单金额。
通过视图结构和Hologres的配合,得到了联邦查询的能力,目前在万里牛的应用中带外表数据查询时长<10s,如果只涉及内表查询运行时长<1s。当然由于没有流计算的参与,目前的维度表是从离线同步到Hologres的,这部分时效性就比较差,同时实时,准实时的统计直接从ODS层走,计算效率会成为问题。
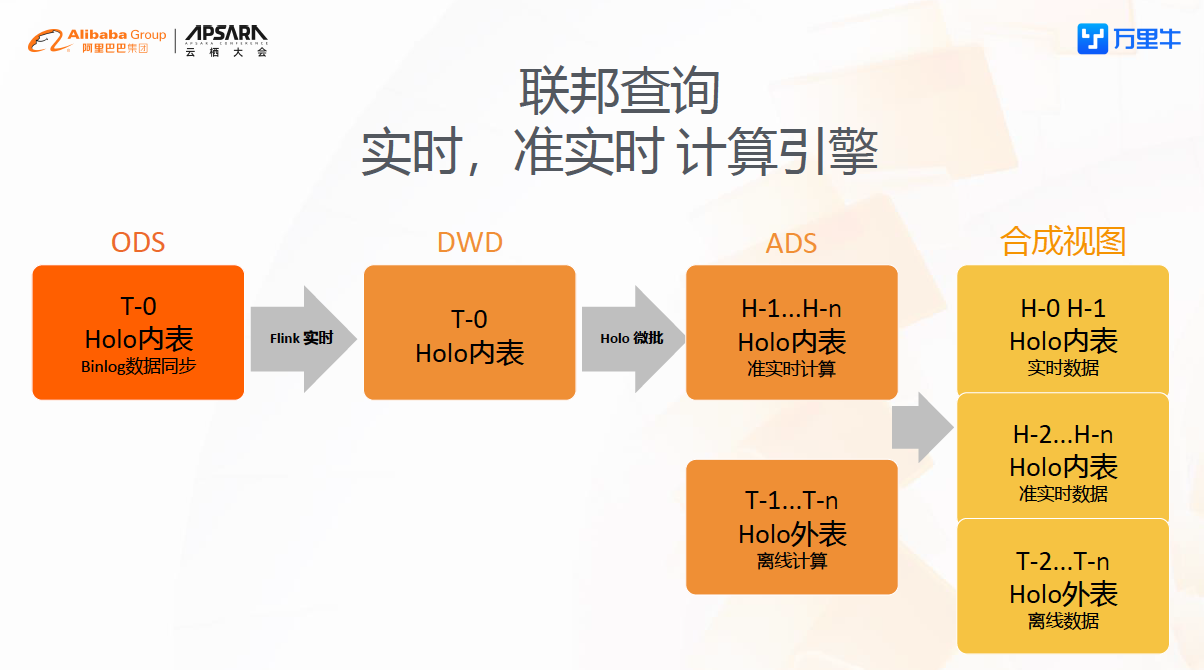
下一步改进的方向是,增加Flink流计算,建立实时数仓的DWD和DIM层。Hologres采用LSM树,支持细粒度的实时更新,同时内表支持主键,能够保证准确一致性。我们可以将Hologres内表作为Source送入Flink做流计算,再把Hologres内表作为Sink存储计算结果。通过Flink流计算得到DWD和DIM层。
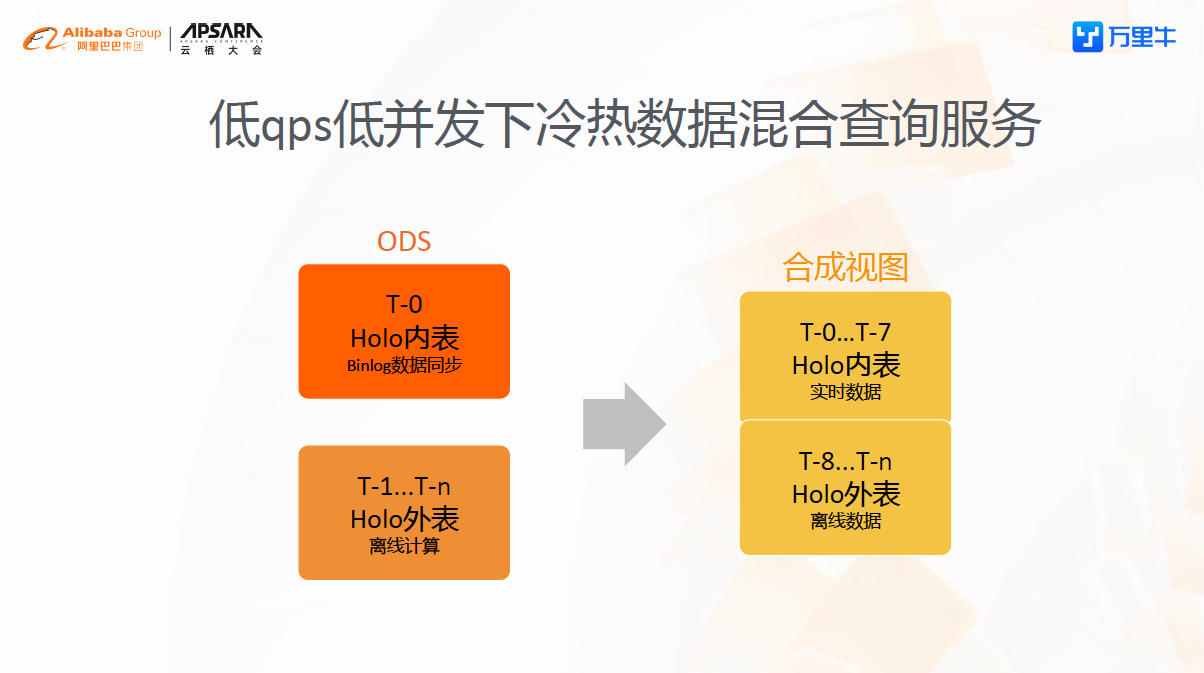
低QPS,低并发下的冷热数据混合查询服务的业务场景是万里牛有类似库存流水查询这样的应用,特点是数据是日志型的,数量很大,基本都是读操作;放在RDS或者ES里很浪费,目前万里牛的做法是把数据实时同步到数仓,利用Hologres和MaxCompute冷热分层,既能保证热数据的查询效率,又可以节约成本,能够让一份数据多点应用。
(3) Hologres目前的不足
在使用Hologres期间也发现的一些不满足实际需求的地方:多数据源实时同步的问题,StreamX的同步任务,无法灵活的配置多数据源;资源隔离的问题,无法像MaxCompute一样做资源隔离,链接数控制需要自己来做;Java API要求版本和费用过高。
更多关于大数据计算、云数据仓库技术交流,欢迎扫码查看咨询。

【免责声明:CSDN本栏目发布信息,目的在于传播更多信息,丰富网络文化,稿件仅代表作者个人观点,与CSDN无关。其原创性以及中文陈述文字和文字内容未经本网证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本网不做任何保证或者承诺,请读者仅作参考,并请自行核实相关内容。凡注明为其他媒体来源的信息,均为转载自其他媒体,转载并不代表本网赞同其观点,也不代表本网对其真实性负责。您若对该稿件由任何怀疑或质疑,请即与CSDN联系,我们将迅速给您回应并做处理。】
